一、产品简介
通过采集微博、小红书、论坛、问答等主流社媒阵地和京东、天猫等主流电商评论的消费者原生内容数据,对内容进行提炼与分析,聚焦于发现故事人设、场景、痛点;从行业、圈层、个性化场景等不同视角剖析故事内容及人群画像特征,进而挖掘产品新机会和了解触达消费者产生共鸣的营销内容动向,指导企业产品营销策略、消费者沟通策略。
二、数据说明
数据来源: 1)社媒数据:微博、小红书、论坛、问答、京东、天猫。 2)电商数据:天猫和京东,目前主要集中在美妆个护和食品饮料的高销量商品评论数据且覆盖从2022年1月起至今。
更新频率:按月更新,每月15号更新前一个月数据。
三、指标说明
| 指标 | 含义 |
|---|---|
| 声量 | 代表内容的影响力。具体是指按URL采集到的,或命中关键词的数据量,若同一条数据被匹配多次,声量记1。 |
| 上升指数 | 某人设/场景/痛点某个时间对比在过去时间段内波动增长情况,Rising_A1=(内容声量-历史时间段平均声量) /(历史时间段平均声量+1),排除平均声量=0,所以+1。 |
| TGI(Target Group Index,目标群体指数) | TGI=[目标群体中具有某一特征的群体所占比例/库中具有相同特征的群体所占比例]标准数100。反映目标群体在特定研究范围内的强势或弱势,其中TGI指数等于100表示平均水平,高于101 代表具有该特征的用户对活动的关注程度高于整体水平。例如:人设=美妆达人的TGI计算逻辑 。TGI :(分子/分母)100 分子:筛选条件下“美妆达人”人设人数/筛选条件的所有人设人数 分母:库内“美妆达人”人设的人设/库内所有人设的人数; |
| 规模等级 | 用户量参考约值:按目标内容采集微博小样本圈层用户量占比*微博用户量基数,用户量参考约值分级如下:Tier I:市场用户量约亿+;Tier II :市场用户量约千万+;Tier III:市场用户量约百万+;Tier IV :市场用户量约十万+;Tier V:市场用户量约万及以下 |
| 推荐指数 | 人设、场景、痛点组合的共线声量在TOP10组合声量之合的占比 |
| 故事分数 | 通过文本的情感、分类、实体密度及丰富度综合得分和搜索相关性得分结合计算而得综合评分,区间在【1-100】 |
| NSR | 净情感度(Net Sentiment Rate),用于衡量该产品的整体情感表现,NSR=(正面情感值-负面情感值)/(正面情感值+负面情感值)*100%。 |
四、系统功能操作
1. 行业故事
洞察行业品类消费者人群画像,分析消费者有哪些场景需求,主要表现热议/上升的人设、场景、痛点及变化趋势,且深入细分人群对比分析。
1.1 筛选器功能
-
行业选择: 可下拉选择某一/多行业包括美妆个护、食品饮料、网络服务、服饰鞋包、汽车、家用电器、3C数码、母婴用品,其中包含一级细分品类有美妆个护、食品饮料、汽车、家用电器、3c数码等行业。

- 高级选项:
有性别、龄范围、城市级别、城市/省份、平台选择、文章类型等多种细分维度筛选;
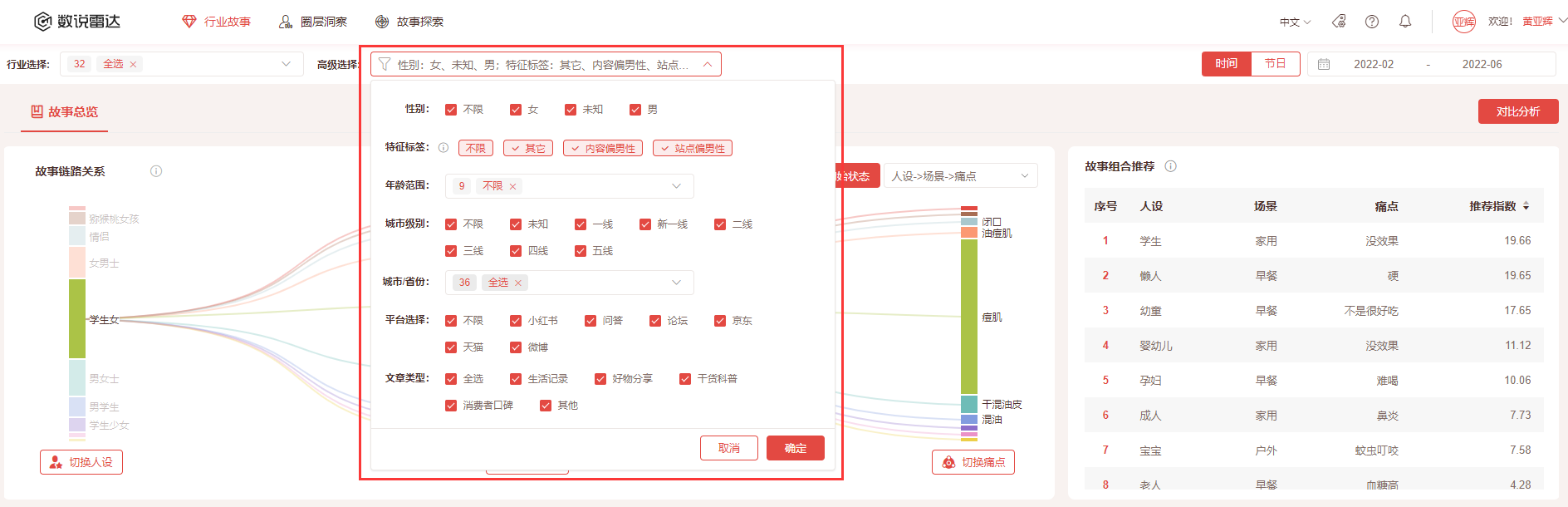
- 其中【特征标签】:内容偏男性、站点偏男性、其它;其中内容偏男性通过发帖内容包括讲到男性或者男性语言等构建的标签;站点偏男性通过站点属于游戏、科技、虎扑等偏男性构建的标签;
- 其中【平台维度】:小红书、微博、论坛、问答、京东、天猫。
-
其中【文章类型】:生活记录、提问、产品感受、科普文等文章分类类型,非上述类型则归类到其他类型中。
-
时间筛选: 目前设定最大时间跨度为5个月,历史数据回溯开始时间从2022年1月份开始

- 节日筛选:
按照"节日"进行筛选,当前有春节、元旦节、妇女节、214情人节可以切换

1.2 故事总览
故事链路关系:
① 恢复链路的默认状态
② 切换链路关系路径
③ 更换不同的人设
④ 更换不同的场景
⑤ 更换不同的痛点
⑥ 点击选中节点可联动组合推荐和人设分析/场景分析/痛点分析

故事组合推荐:
可以跟左侧故事链路关系做数据联动,查看对应的推荐指数

1.3人设分析
统计【热门人设和上升人设】列表,剖析人设趋势 ,人群基本特征性别、年龄、城市级别以及生活状态、爱好词云,全方位洞察人群特征。
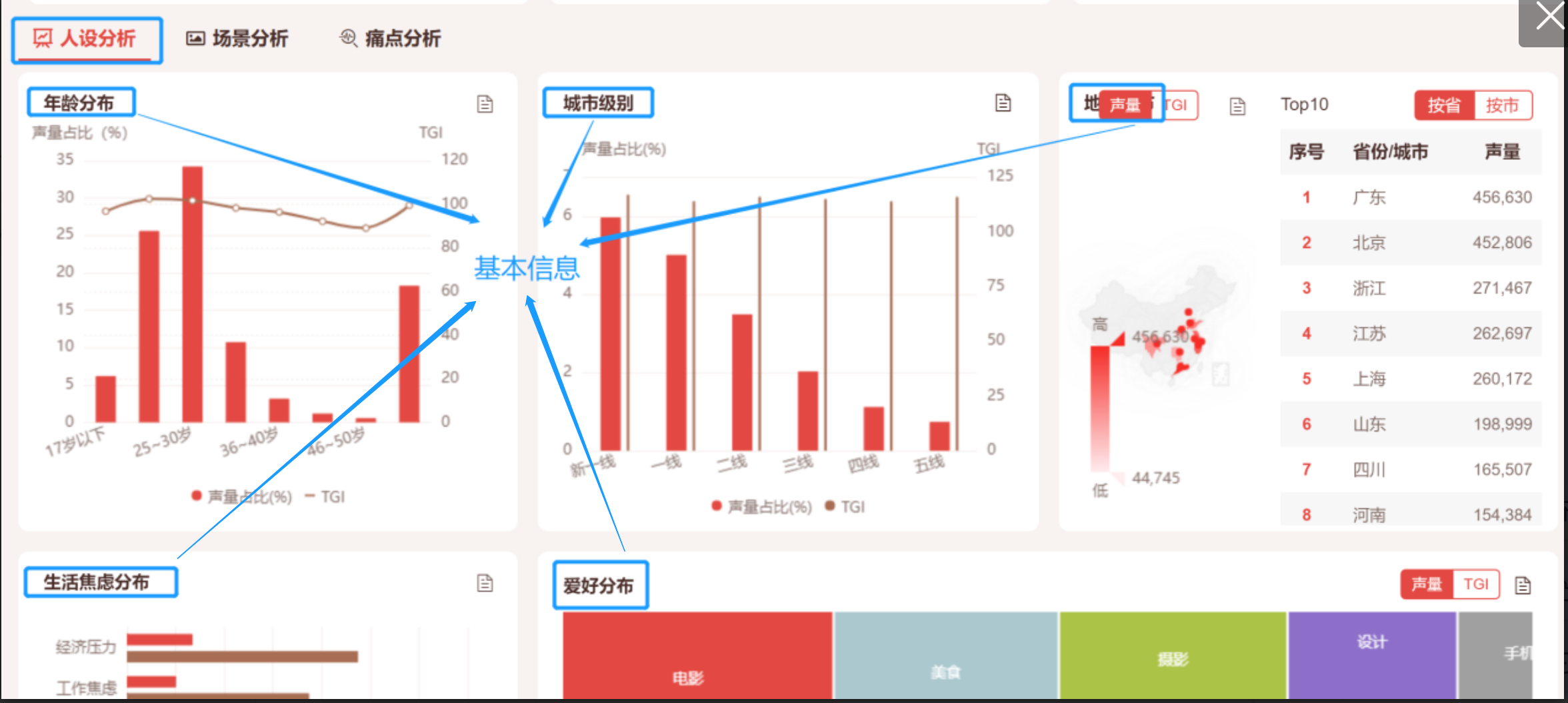
核心功能说明: 选择热门和上升人设数据行可联动分析人群特征所有分析维度组件,亦可洞察不同人设的特征差异;
1.4场景分析
统计【热门场景/上升场景】列表,分析趋势,关联的提及品类属性高频分类和特征高频词分布以及原文list,推荐活跃场景帮助企业优化品类,获知场景化营销创意。

核心功能说明: 【热门痛点/上升痛点】列表,按声量/TGI 指标排序,可分析具体痛点趋势 , 在某痛点下分布在哪些场景、哪些人设,关联痛点的提及品牌和提及品类分布情况,联动原文看看具体痛点讲些什么。 默认是某行业/品类下所有痛点的分析;
1.5痛点分析
统计【热门痛点/上升痛点】列表,分析趋势、原文list、人设分布、场景分布、提及品牌/品类、原文list。痛点来自哪些人设\场景,提及top品类和品牌分布是哪些。

核心功能说明: 【热门痛点/上升痛点】列表,按声量/TGI 指标排序,可分析具体痛点趋势 , 在某痛点下分布在哪些场景、哪些人设,关联痛点的提及品牌和提及品类分布情况,联动原文看看具体痛点讲些什么。 默认是某行业/品类下所有痛点的分析;
1.6 对比分析
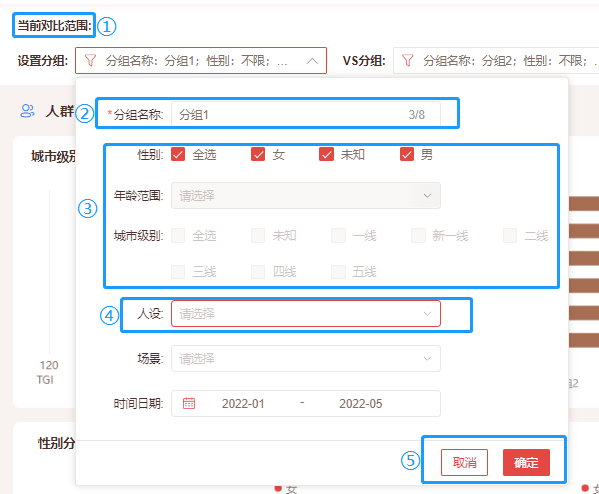
① 默认入口带入筛选的行业或者行业品类。
② 设置对比分组名称。
③ 性别、年龄、城市只能设置其中任一条件。
④ 人设或者场景可搭配其他条件设置。
⑤ “确定”后设置条件保存成功,“取消”则不保存。
人群画像对比:
①-⑤城市级别、年龄范围、性别、生活焦虑状态、爱好分布均是按照top10 的TGI统计进行对比

场景需求对比: ① 高频场景:按声量统计top25的高频场景分布分析对比,点击“场景”可联动对应分组痛点 ② 需求痛点:默认分组痛点概览对比,可对比分析某场景的痛点词云分布 品类品牌对比: ③ 热议品类或者品牌,按TGI 的top 10统计,可对比分析差异化

2 圈层洞察
围绕人的兴趣爱起居的圈层剖析,用户能获取圈层规模、趋势、活跃情况、跨圈层人群重合度等,圈层人群画像、故事场景需、热议的品类品牌功效、痛点内容等提取内容创意灵感,触达消费人群,产生共鸣。
2.1筛选区功能
-
圈层选择: 可下拉复选50+圈层筛选,包括饭圈、影视圈、二次元圈、公益圈、美妆圈等等,可以根据圈层需求进行选择

- 高级选项:
有性别、年龄范围、城市级别、城市/省份、平台选择、文章类型等维度;

- 其中【平台维度】:小红书、微博、论坛、问答、京东、天猫。
-
其中【文章类型】:生活记录、提问、产品感受、科普文等文章分类类型,非上述类型则归类到其他类型中。
-
时间筛选: 目前设定最大时间跨度为3个月,历史数据回溯开始时间从2022年1月份开始

- 节日筛选:
按照"节日"进行筛选,当前有春节、元旦节、妇女节、214情人节可以切换
2.2 圈层总览
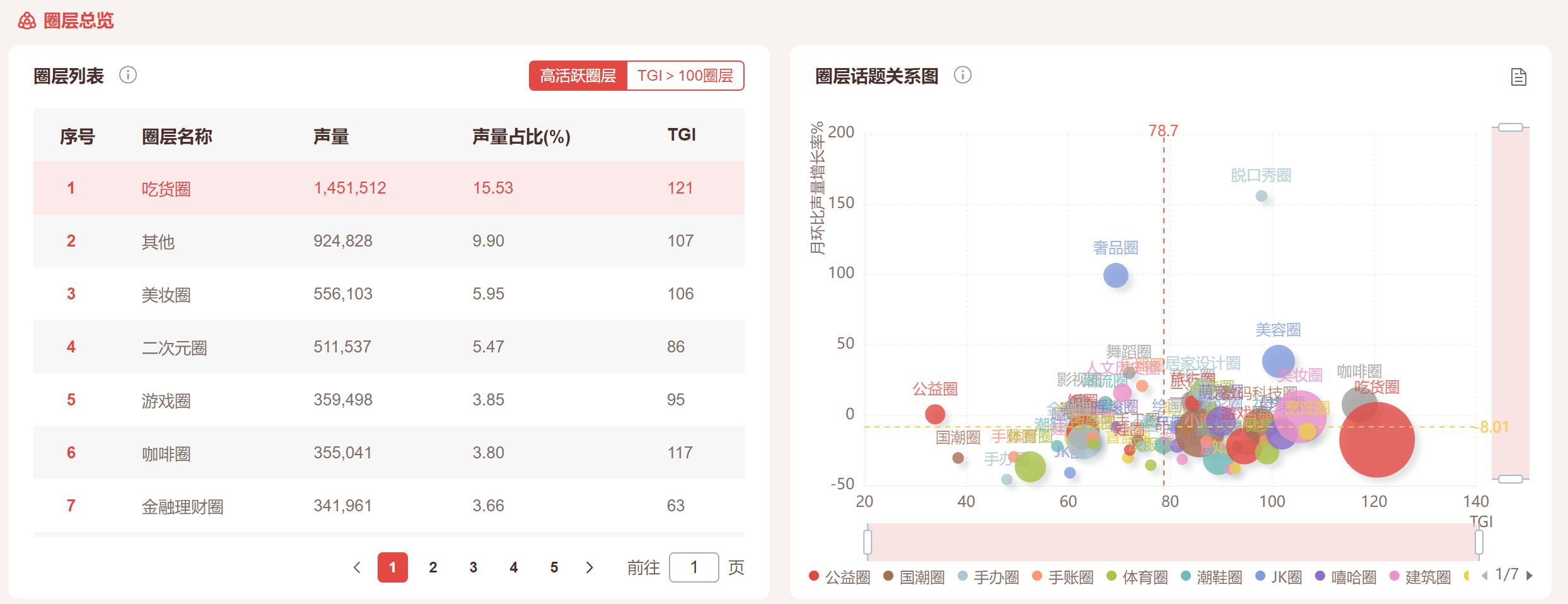
左侧:圈层列表总览:
- 高活跃圈层:即按声量排序统计;
- TGI大于100圈层:按TGI大于100的圈层;
右侧:圈层月环比增长总览:
- Y轴:末月声量增长率%=(筛选时间范围末月声量-上月声量)/上月声量*100%;
- X轴:TGI,目标人群圈层人数占比/(业务库下目标圈层人数/业务库下所有人数)x 100;
- 圈层大小 = 目标人群中圈层声量;
2.3 圈层分析
单独圈层分析,包括圈层级别,圈层规模,圈层重合度,圈层趋势,圈层活跃平台分布及圈层的人群画像、故事场景和提及品类品牌是哪些
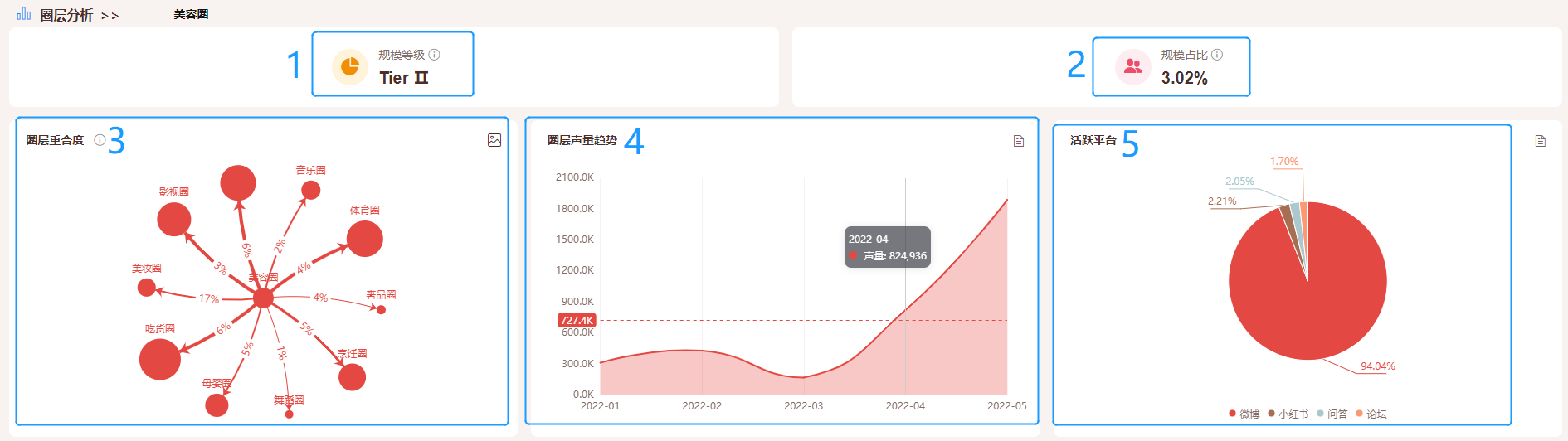
1)规模等级:按目标内容采集微博小样本圈层用户量占比*微博用户量基数,用户量参考约值分级如下: Tier I:市场用户量约亿+ Tier II:市场用户量约千万+ Tier III:市场用户量约百万+ Tier IV :市场用户量约十万+ Tier V:市场用户量约万及以下 2)规模占比:圈层用户数/所有圈层总用户数 3)圈层重合度:以目标圈层为中心,两个或多个圈层的关联度,圆点越大规模越大,线条百分比越大表示重合度越高 4)圈层声量趋势:统计目标圈层声量趋势 5)活跃平台:目标圈层在各个平台分布占比
2.4 人群画像
目标圈层人群画像,包括性别、年龄分布、爱好词云、地区分布、城市级别、热议话题等维度剖析该圈层的人群画像

2.5 故事场景
目标圈层讨论的场景是什么,有哪些常见人设和痛点,以及可以查看具体故事原文;
① 场景可以联动人设和痛点、原文list;
② 人设和痛点可以联动原文;

2.6 热议品类
可以查看圈层人群关注的品类分布情况亦可聚焦筛选某个行业下的一级品类、二级品类分布、提及品类下的特征维度分布情况及维度下的需求高频词、情感走势、原文等剖析。
①一级品类top10
饼图, 统计筛选条件下某个/些圈层人群提及品类分布,且可筛选行业聚焦行业下的一级品类分析,取声量top10,展示声量分布占比。

②二级品类top10
竖向柱状图,统计筛选条件下某个/些圈层人群提及品类分布,统计声量和TGI,按声量排序取top10。
X轴:品类名称
Y轴:声量和TGI

③特征分类
雷达图,统计筛选条件下某个/些圈层人群提及需求归类到特征分布情况,查看声量,分类维度包括:功效/功能、成分/原料/材质、触感/口感/体验、性格/设计/形态、包装、气味/味道、科技/工艺等维度
指标:声量及声量占比,默认高亮最高声量的分类;

④特征高频词
词云图,统计筛选条件下某个/些圈层人群提及特征分类下的高频词,统计指标:声量

⑤特征情感趋势
堆积趋势图,统计筛选条件下某个/些圈层人群热议品类下的特征分类及特征词的高频词的情感走势,统计维度包括正面、负面、中性的声量。

⑥热议品类-原文展示

联动说明: a) 一级品类top10联动二级品类/特征分类/特征高频词/特征情感趋势及原文展示 b)二级品类联动特征分类/特征高频词/特征情感趋势/原文展示 c) 特征分类联动特征高频词/特征情感趋势/原文展示 d) 特征高频词联动特征情感趋势/原文展示
2.7 热议品牌
① 关注品牌分布
竖向柱状图,统计筛选条件下某个/些圈层人群提及品牌分布且可聚焦筛选某个行业下的品牌,统计声量占比和TGI,按声量排序取top10。点击【品牌】柱子可联动其他图表下钻分析;
X轴:品类名称
Y轴:声量和TGI

② 产品榜单
榜单表,统计筛选条件下某个/些圈层人群提及品牌下的产品,统计声量和NSR;默认按声量降序排序;点击【产品名称】可联动其他图表下钻分析;

③ 情感趋势
趋势图,统计筛选条件下某个/些圈层人群提及品牌或者产品的情感分布,维度分为正面、负面、中性等的声量及占比按月分析数据;
 ④ 情感高频词
词云图,统计筛选条件下人群提及品牌or产品下特征分类下的高频词声量数据,可切换正面or负面;点击【词】可联动原文;
④ 情感高频词
词云图,统计筛选条件下人群提及品牌or产品下特征分类下的高频词声量数据,可切换正面or负面;点击【词】可联动原文;
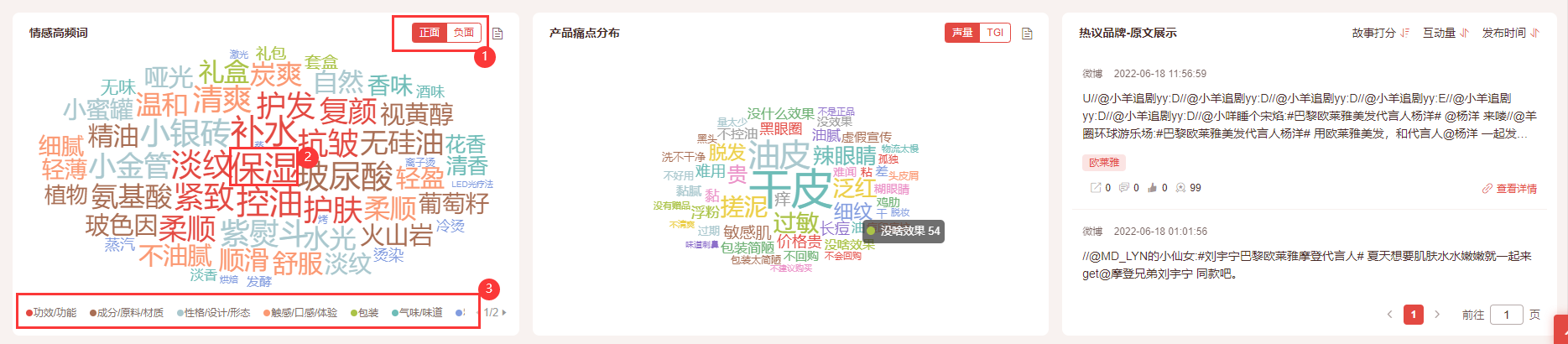 ⑤ 产品痛点分布
词云图,统计筛选条件下人群提及品牌or产品下特征分类下的产品痛点声量数据,点击【词】可联动原文;
⑤ 产品痛点分布
词云图,统计筛选条件下人群提及品牌or产品下特征分类下的产品痛点声量数据,点击【词】可联动原文;
 ⑥热议品牌-原文展示
原文可查看消费者具体表达
⑥热议品牌-原文展示
原文可查看消费者具体表达

2.8 对比分析
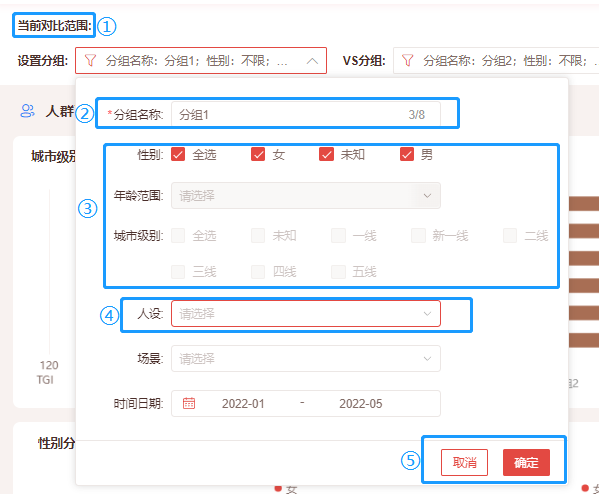
① 默认入口带入筛选的一个或者多个圈层。
② 设置对比分组名称。
③ 性别、年龄、城市只能设置其中任一条件。
④ 人设或者场景可搭配其他条件设置。
⑤ “确定”后设置条件保存成功,“取消”则不保存。
人群画像对比:
①-⑤城市级别、年龄范围、性别、生活焦虑状态、爱好分布均是按照top10 的TGI统计进行对比

场景需求对比:
① 高频场景:按声量统计top25的高频场景分布分析对比,点击“场景”可联动对应分组痛点
② 需求痛点:默认分组痛点概览对比,可对比分析某场景的痛点词云分布
品类品牌对比:
③ 热议品类或者品牌,按TGI 的top 10统计,可对比分析差异化

3 故事探索
依据输入【关键词】细分场景发散型自由探索故事,例如:双十一、618活动洞察消费者需求。
3.1 筛选器功能
通过搜索对应的关键词,进行高级筛选条件,可以探索到对应的故事。【关键词】格式如下:用+连接,表示且关系;用|连接,表示或关系;支持英文括号()组合。例“(宝宝|婴儿|幼儿|儿童|娃)+奶粉”

1.时间筛选:目前设定最大时间跨度为5个月,历史数据回溯开始时间从2022年1月份开始

2.按照"节日"进行筛选,当前有春节、元旦节、妇女节、214情人节可以切换
3.2 创建探索
按目标条件筛选出数据后点击"创建探索"可以新建探索,设置探索名称,创建后可在【我的探索】列表查看。此功能便于保留历史探索记录。

3.2 我的探索
点击"我的探索"可查看历史我创建的探索,亦可跳转至【圈层洞察】【行业故事】,此调整功能会受权限控制。
 功能说明:
仅查我创建:点击可查创建人=登录账号创建的探索数据;
全部:点击全部可查账号所属组织的探索数据;
删除:仅创建人=登录账号的数据可删除,非登录账号的不可操作删除;
行业故事:可带创建探索条件跳转至行业故事模块页面分析
圈层洞察:可带创建探索条件跳转至圈层洞察模块页面分析
功能说明:
仅查我创建:点击可查创建人=登录账号创建的探索数据;
全部:点击全部可查账号所属组织的探索数据;
删除:仅创建人=登录账号的数据可删除,非登录账号的不可操作删除;
行业故事:可带创建探索条件跳转至行业故事模块页面分析
圈层洞察:可带创建探索条件跳转至圈层洞察模块页面分析
3.3 故事探索-故事人设
1)故事人设:统计声量和TGI指标,可以查看top50人设。

3.4 故事探索-故事场景
2)故事场景: 统计声量和TGI指标,可以查看top50场景。

3.5 故事探索-需求痛点
3)故事痛点:统计声量和TGI指标,可以查看top50痛点。

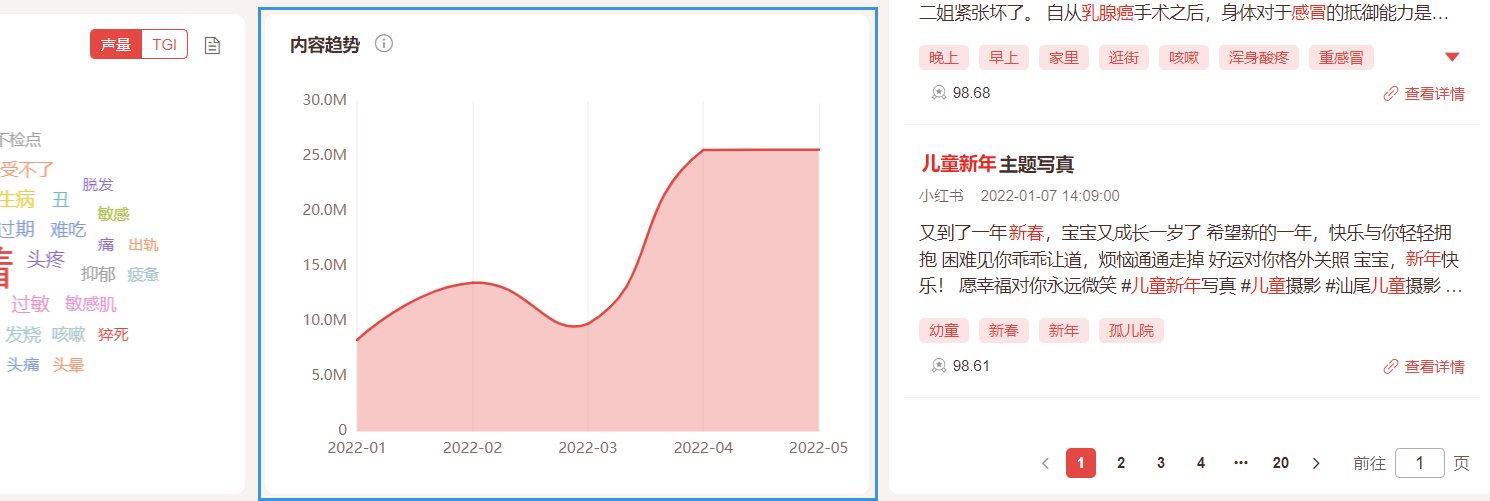
3.6 故事探索-内容趋势
4)内容趋势:默认筛选条件所以内容趋势分布,可被人设、场景、痛点联动或者组合联动
3.7 故事探索-原文展示
5)原文列表:可按故事打分、互动量、发布时间来排序;

五、核心算法说明
1.新概念故事会识别算法
专用于故事会的命名实体识别算法,是指识别文本中具有特定意义的实体。通过人工标注文本中不同类型的实体,如人设,痛点,场景等,训练基于深度学习的模型,自动提取文本中对应类型的实体。
2.新概念全品类识别算法
专用于全品类的命名实体识别算法,是指识别文本中具有特定意义的实体。通过人工标注文本中不同类型的实体,如品类,品牌,产品型号,颜色等,训练基于深度学习的模型,自动提取文本中对应类型的实体。
3.故事打分算法
基于新概念故事会识别算法、新概念全品类识别算法和文本分类算法,对一段文本进行多维度打分,如情感丰富度、情感多样性、实体丰富度、实体多样性等,倾向凸显故事元素丰富的内容。
4.广告杂音判断算法
通过人工数据标注不同类型的广告,如微商软文、海外代购、抽奖活动、优惠券信息、旅游推广、培训活动报名、⽂章主动推出含购买链接的产品等广告,基于机器学习模型,实现广告判断。将微博、微信、新闻等数据分为四类:低质量广告、高质量广告、杂音、自发内容,以帮助用户清洗数据和分析广告数据中的有用信息。


产品咨询
020-38061725

微信扫描二维码在线咨询