1、把长文本放在筛选器中,条件搜索应该怎么写?
答:条件搜索是一个文本表达式,用+ | () !四种符号(分别表示且 或 优先运算 否)将关键词连接起来,表达搜索意图。此外如果关键词中本身存在这四种符号,需要用进行转义\,如 \+
举例来说,如果想要搜索关键词"C++",表达式的写法是:C++. 在复杂场景下,可以组合出类似如下表达式
((中国|C++)+贸易战)|(Steve Jobs+!关税)
或
(((中国|美国)+贸易战)|(特朗普+关税))+!(搞笑|段子)
!(搞笑|段子)表示 长文本中不包含搞笑或者不包含段子!(搞笑+段子)表示 长文本中不包含搞笑 段子两个词
2、为什么选择某个字段分类统计后,计算总数与记录数不一致?
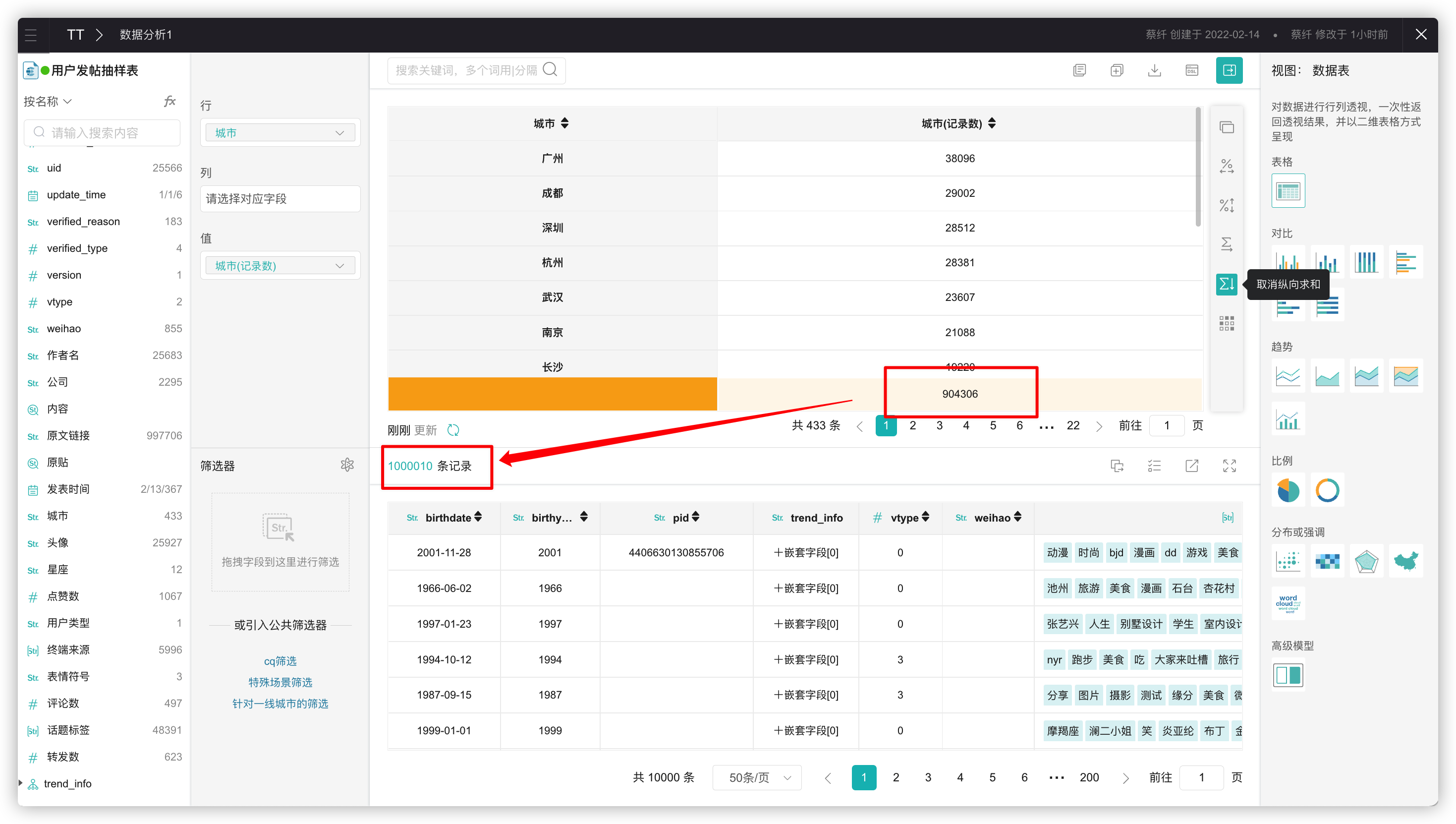
答:因为[城市]字段部分内容数据存在为空值,未统计到,因此总数值不一致。
3、为什么筛选21-22年的数据,结果出现20年12月的数据?

答:因为该字段时区配置的问题。数据写到库中的时候默认记录的是当前的时区(UTC-8);但是查询的时候如果字段没设置的话,会使用默认的utc时间来查,这样会存在时区误差。需要核查下数据源中字段的时区类型。

4、为什么页面报字段基数超出阈值


答:系统默认阈值,是为了保护集群(防止误查询给集群造成压力)。若实际业务强烈需求,可以在数据管理中查看该表的所属集群信息,找下该集群负责人调整下阈值。 即使配置筛选器后仅剩2K多的数据,但因为计算阈值的时候没有计算筛选器,所以还是会报提示。
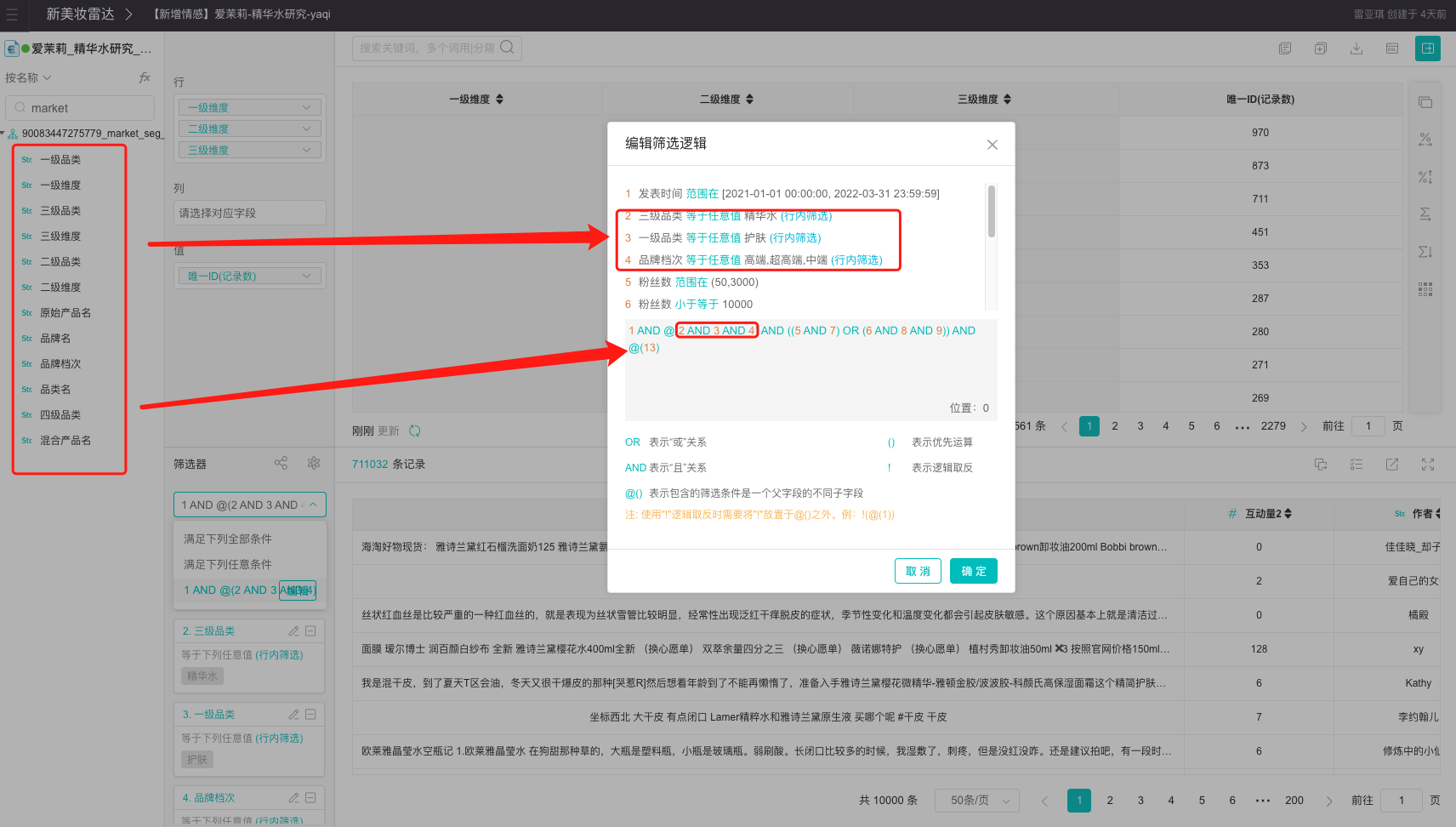
5、为什么我配置了筛选【三级维度】(嵌套字段)为非空值,还是查出来很多空值
 答:因为【三级维度】13跟 2/3/4 属于同个嵌套字段,需要在同个@()里面声明,不然ES会按 或 逻辑执行。
答:因为【三级维度】13跟 2/3/4 属于同个嵌套字段,需要在同个@()里面声明,不然ES会按 或 逻辑执行。
6、为什么三级维度出来的维度缺失了?”补水”这个词,没有在透视表里面出现的,但行列筛选是有的,而且数据量也不小
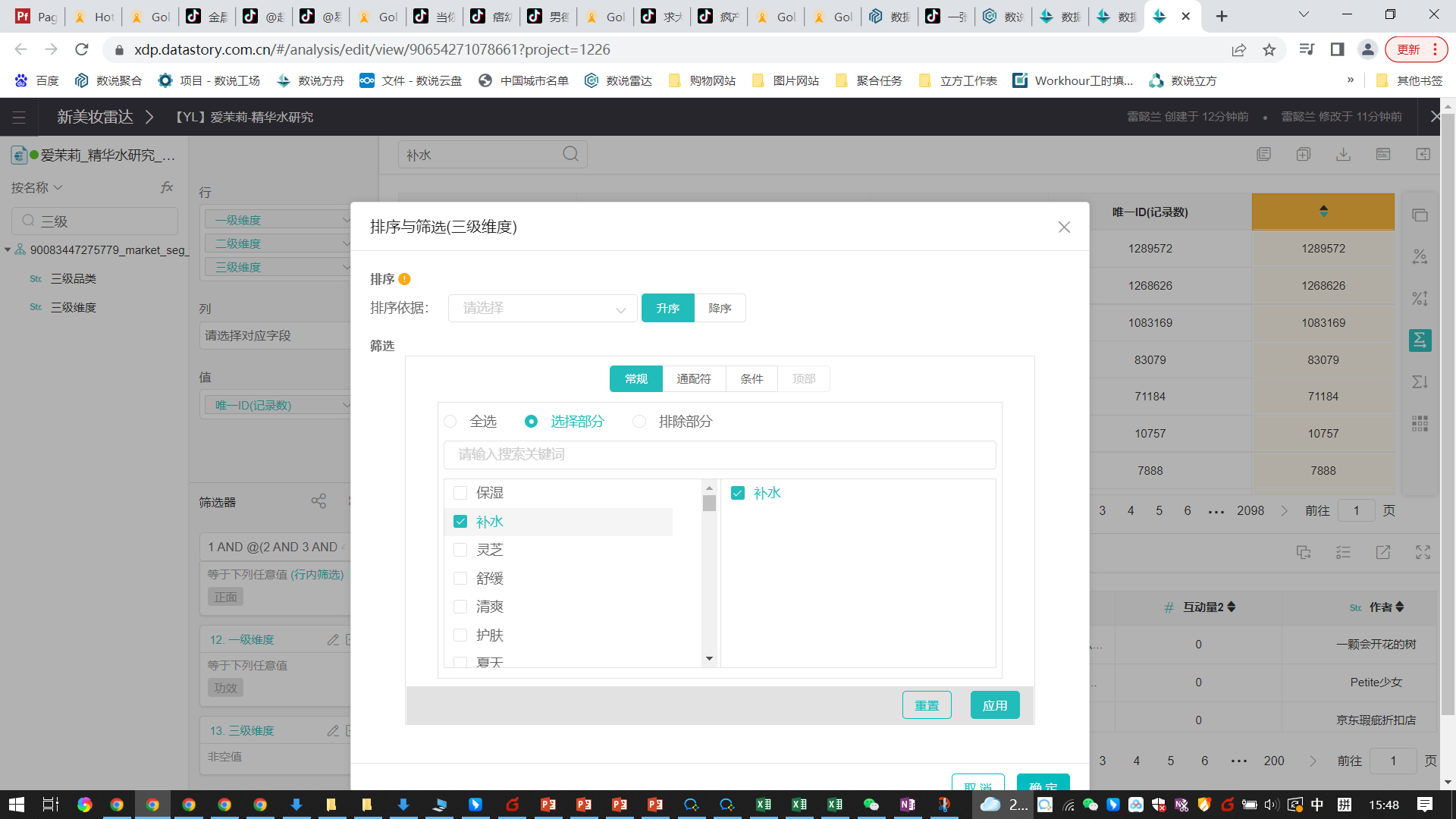

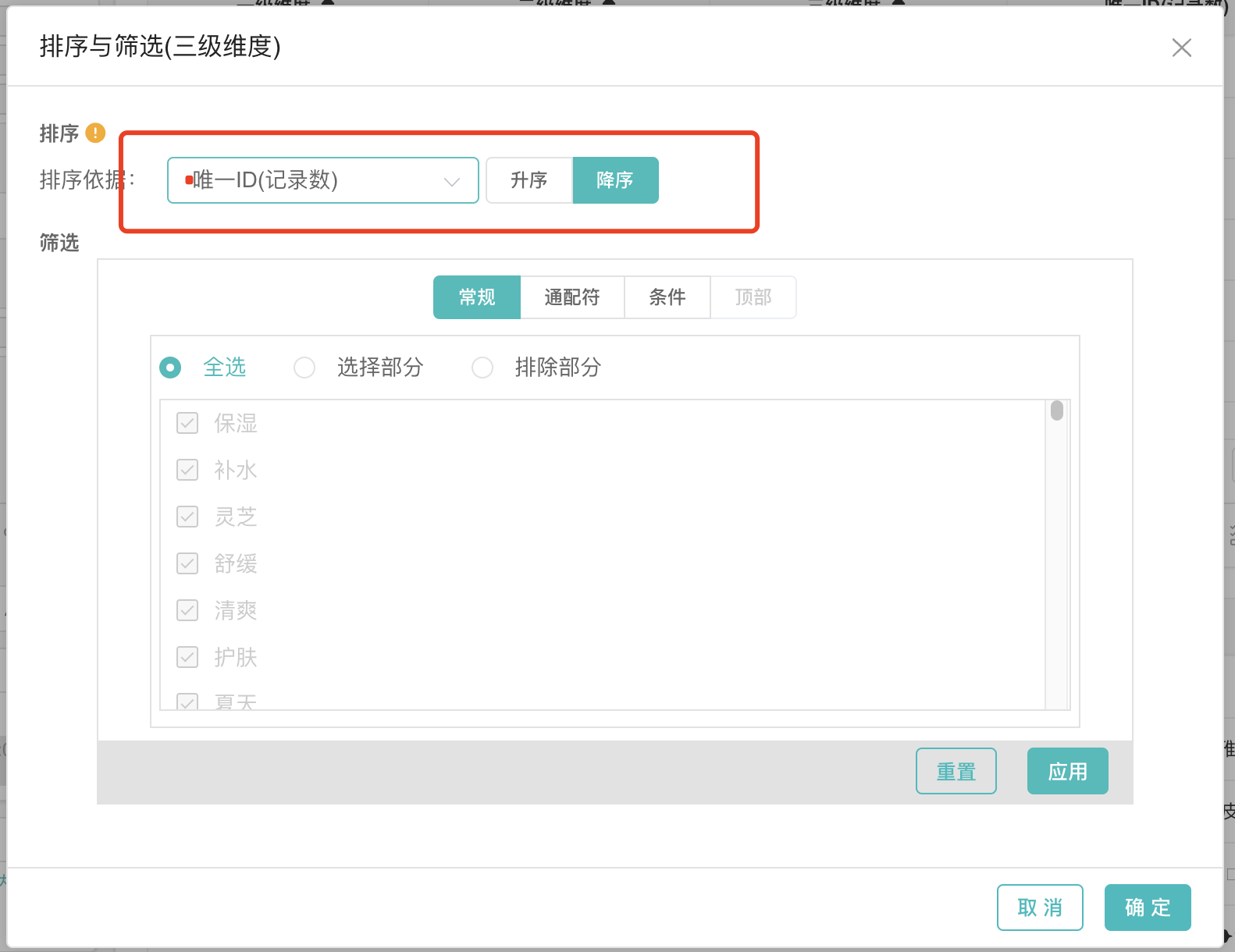
答:分析模块中的透视表有窗口限制,维度只能展示1500个。若超出该阈值,则只会随机展示1500。若用户关心的是维度数量级多的前1500条。可以在行配置中配置排序。这样能保证窗口取到数据量最多的1500条维度。
7、为什么嵌套字段品牌名筛选了不等于“迪奥”的数据,记录中还是有迪奥的数据
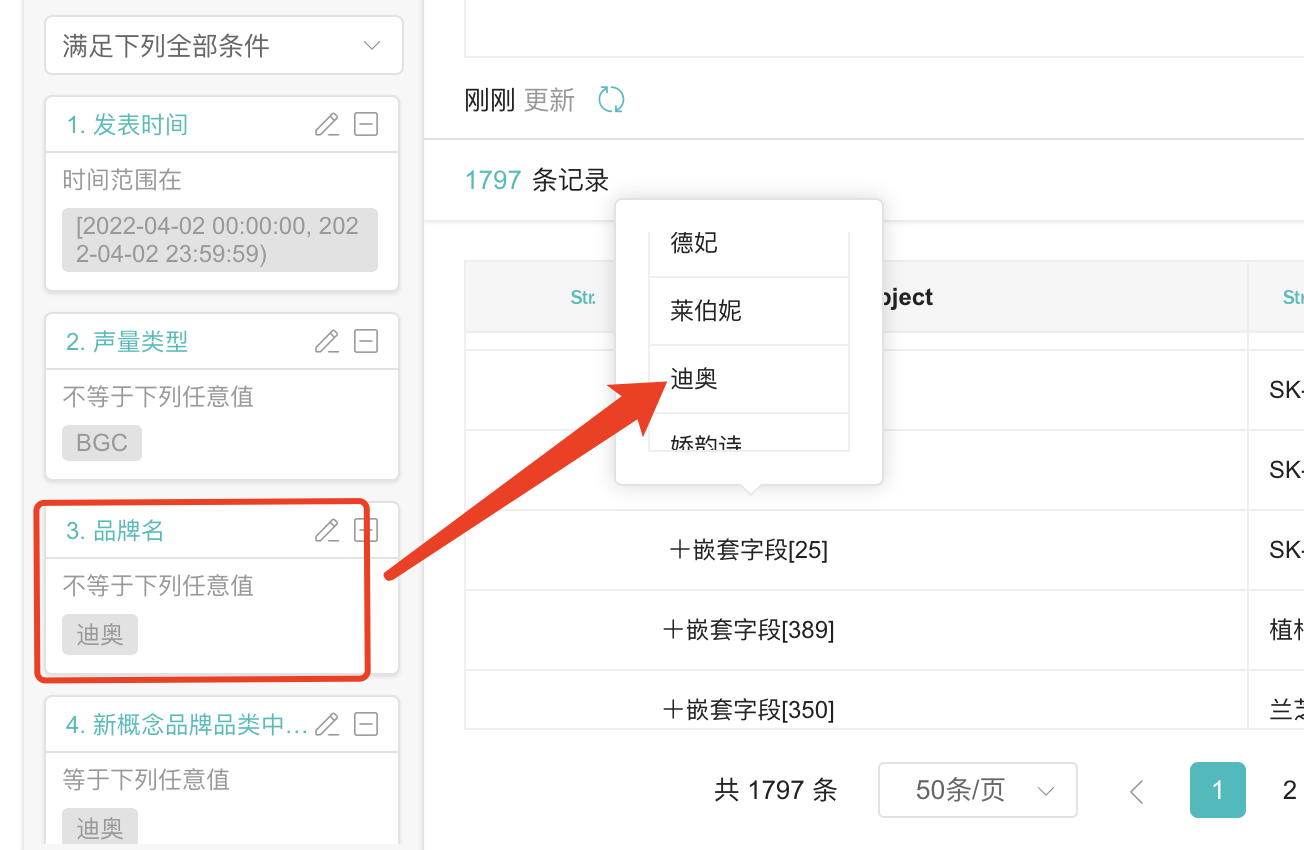
答:看看 嵌套字段筛选指引
8、为什么数据记录数多了,可是聚合出来的品牌数少了
选择【品牌数-全部记录】的时候,品牌数=75;
选择【品牌数-非空值】的时候,品牌数=98,
选择全部记录的时候的数比,选择非空值的数还小。
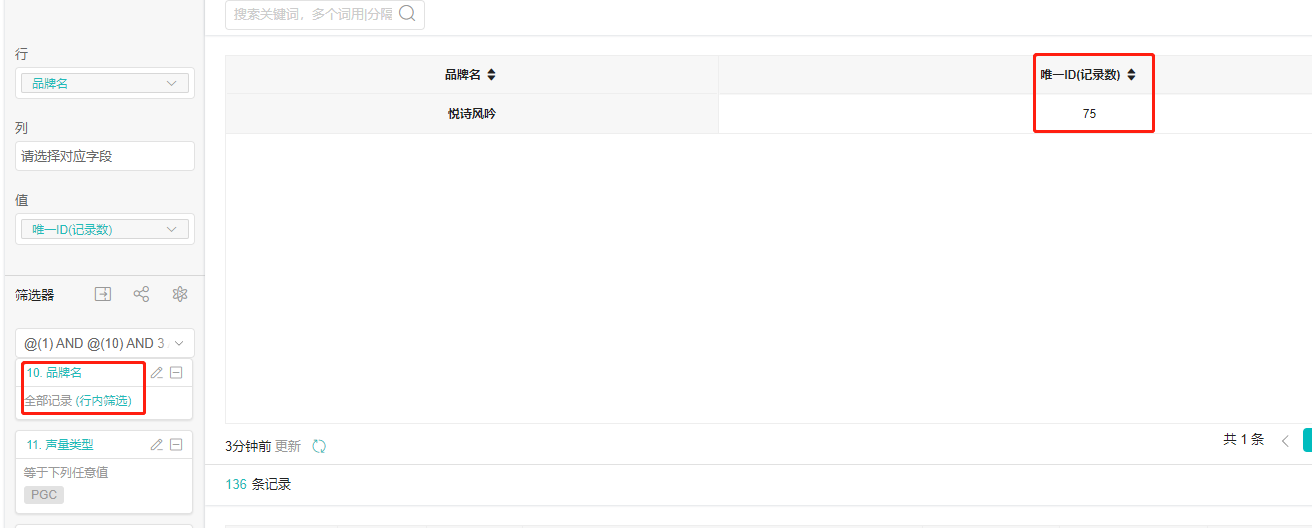
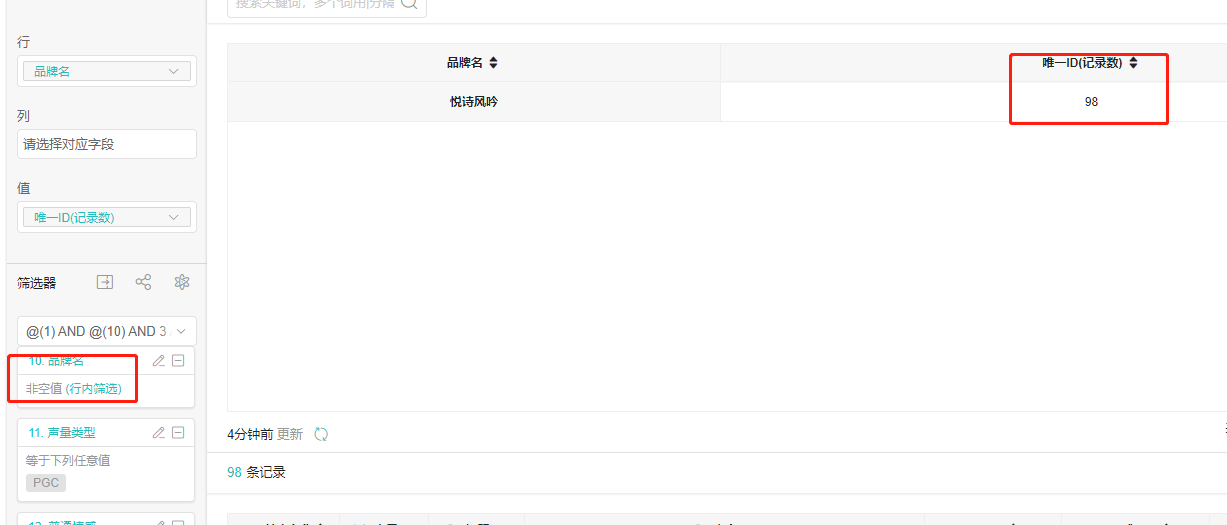
答:因为嵌套字段。
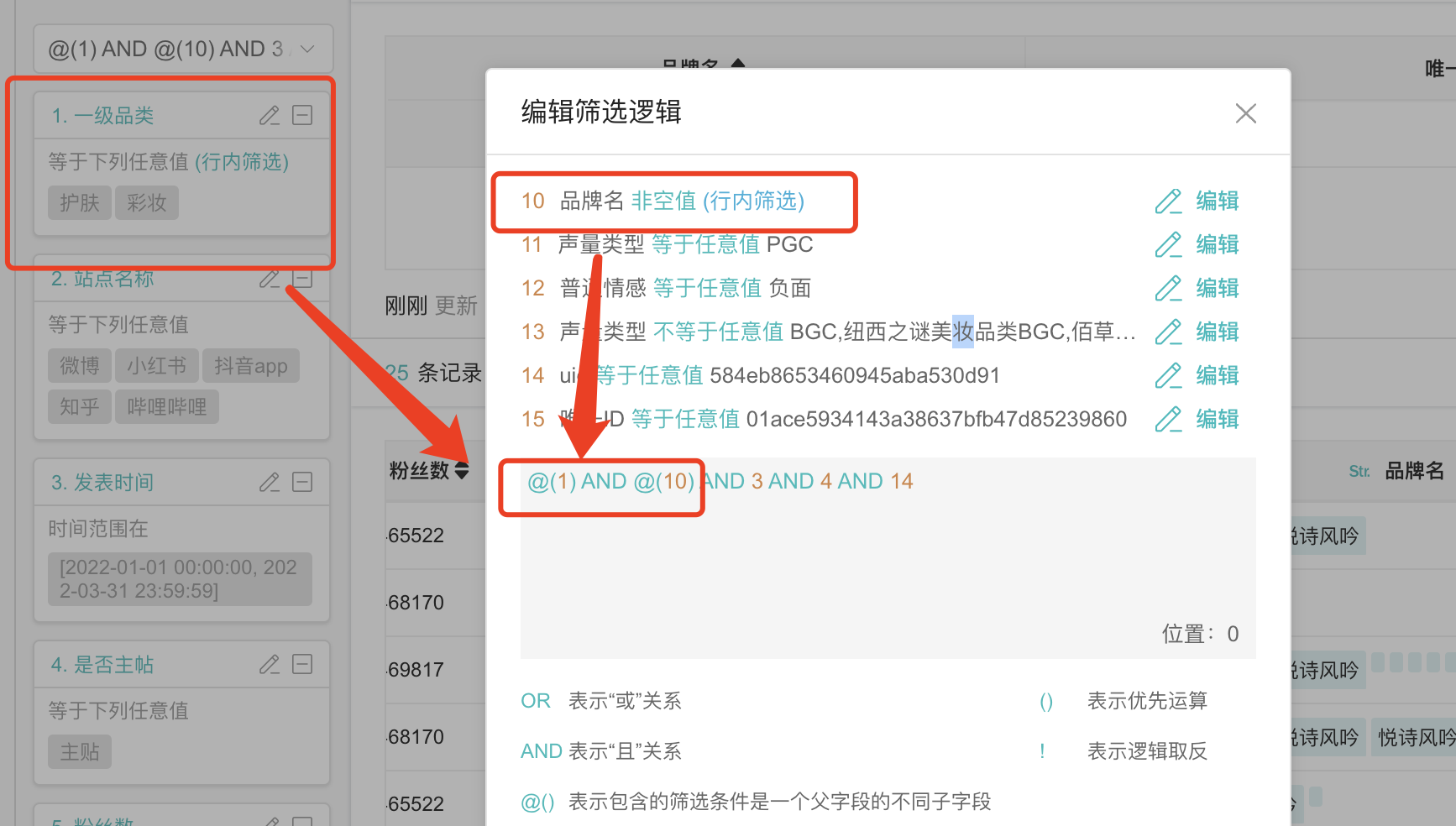
- 1和10 是同个嵌套字段,它们没有放在一个@里面,行内筛选就会随机取最后一个嵌套字段10作为行内筛选条件。
- 当10为全部记录时,相当于只用了1作为筛选条件,1也是行内筛选条件
- 当10为非空时,就是1和10 作为筛选条件,10是行内筛选条件
那下面这条数据,他满足了@1 and @10,但在基于1行内筛选统计的时候,品牌名为空。基于品牌名非空行内筛选统计时候,悦诗风吟=1。

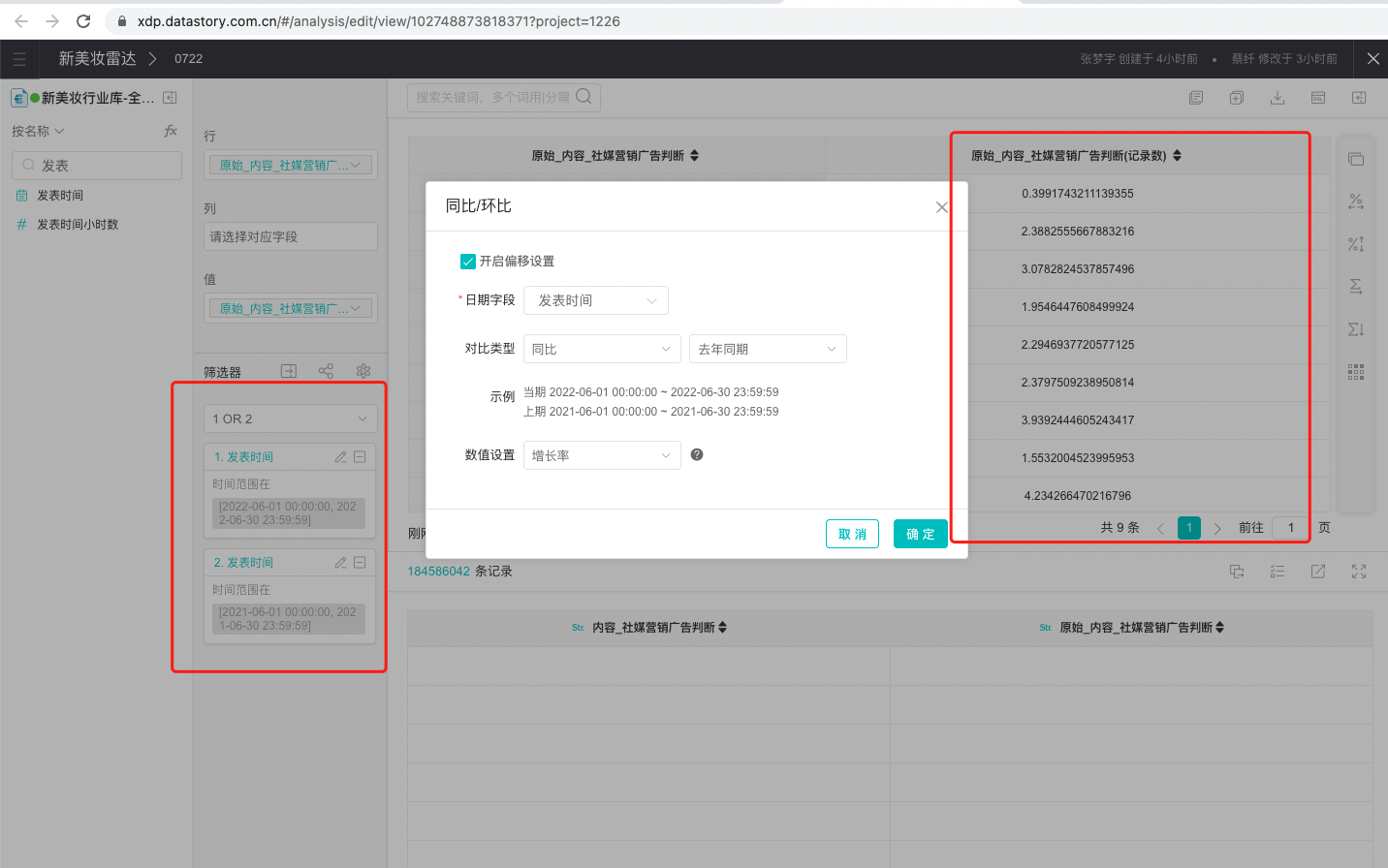
9、为什么数据做同比分析时,增长值/率为空?

答:新美妆行业库-全(别名联合索引,勿操作)该数据源配置了数据路由。依据筛选器中的发表时间范围判断指定的数据路由。
图中指定了发表时间为6月份,因此指向 Q2这个数据源中去做查询,不用全库查询,这样聚合效率更高。
若想实现该场景下的同比环比,可通过以下方式实现。
10、方舟一直处于加载状态 但又没有显示加载中之类的提示?

答:原因可能有多种,您试试以下解决方案
- 1:确认下网络情况,若您的网络状况良好,往下看
- 2:您别的账号登录过雷达或者聚合,没有退出
- 3:您的浏览器是edge,试试ctrl+shift+r
11、对行字段配置了筛选逻辑,但聚合结果不正确

A:因为 学校 是数组字段,该版本ES用不支持数组字段如此操作,建议使用非数组字段作为「值」。


产品咨询
020-38061725

微信扫描二维码在线咨询