数据可视化本质上是一种对数据的某个切面进行展示的过程。所以无论是饼状图、柱状图或是一个下拉列表,其背后对应的一定是一个数据集(dataset)。
一般情况下,这个数据集不作为直接交付物存在,但它以不同的形态存在于各种中间环节——作为分析模型的输出、数据应用(可视化)的输入。

我们很少谈论数据集的格式,在常规分析工作中,它可能存在于分析师得到的立方工作表或Excel文件中,在泛雷达项目的建设过程中,它更多是存在于前后端对接JSON中。
组件本身会带有初始化的数据集,这些数据是静态的,可以编辑的,称之为mock数据。在数据可视化场景下,组件还可能需要对接实时的分析数据,或者实时的原始数据,这类数据在方舟中由分析过程中形成的API提供。
1.组件与数据集
对于图表类组件或者单选、下拉列表等筛选器组件,其背后对应的一定是一个数据集(dataset)来支持其展示数据,以及参与组件间的联动。
tips:筛选器输入框、时间日期、数值范围可以在不接入数据集的情况下,参与组件联动,由用户在交互行为中直接产生联动数据;也可以接入一个数据集,输入框接入数据集可以联想搜索、时间日期可以限制可选范围、数值范围可以限制数值可选范围。
2.数说方舟的数据集结构
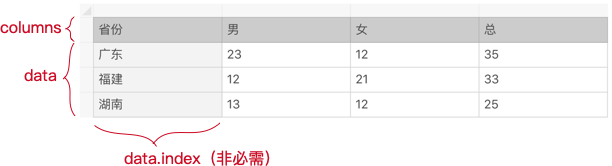
一般情况下,数说方舟的数据集是一个二维表结构,它包含了表头(columns)和数据(data)两部分,data部分有可以分为索引(data.index)和普通数据的部分:
虽然用表格来表达的二维数据已经能够满足常见图表对数据复杂度的要求,但其实你还可以像Excel一样用多个sheet分别装载不同的数据来支撑高度复杂的图表。
3.数据集中的数据类型
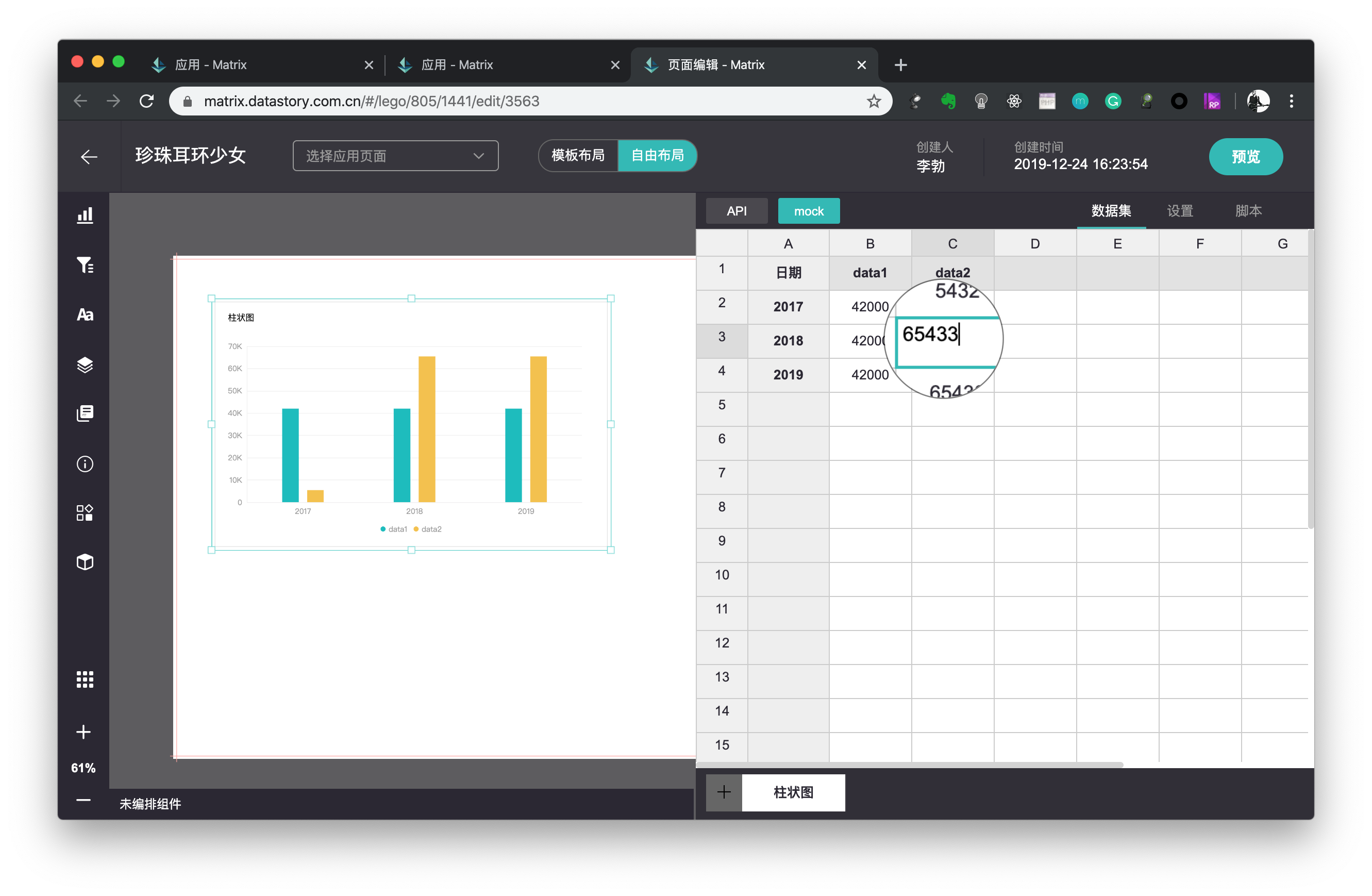
mock数据
每一个图表组件在初始化组件时,默认渲染mock数据。用户可以编辑mock数据得到自己想要的图表。
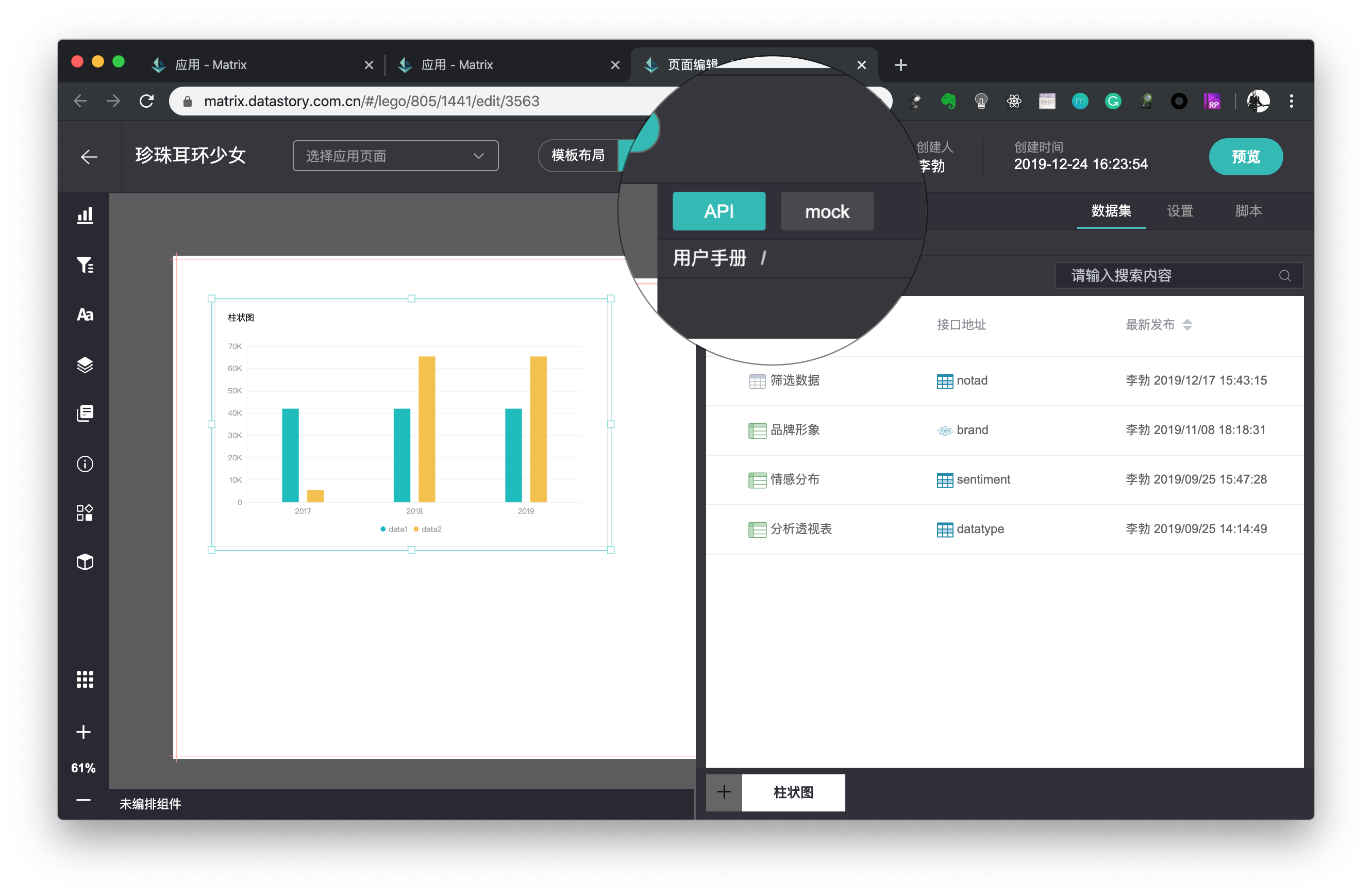
API数据
如果用户已经在分析阶段发布了自定义API,可以设置组件对接API,以渲染动态统计的数据
4.数据集再加工
对于数据集的再加工,有时候可以用于对分析模型的修正,有时候可以用于对可视化的优化。无论怎样,数据再加工的需求是存在并将长期存在的。例如:
- 按照业务要求对“一线城市”、“二线城市”、“海外”、“港澳台”这类值进行排序;
- 实现-1、0、1到“负”、“中”、“正”的转换;
- 当进行聚合操作(aggregation或group by)的时候,对于无法得到的记录数为0的情况,我们手动在数据集中补上它;
- 对排序之后的数据进行筛选,例如只截取数据集的头部数据。
对于mock类型的数据集,可以直接对每一个单元格进行编辑。对API类型的数据集,数说方舟提供了一系列的数据集再加工方案。
排序
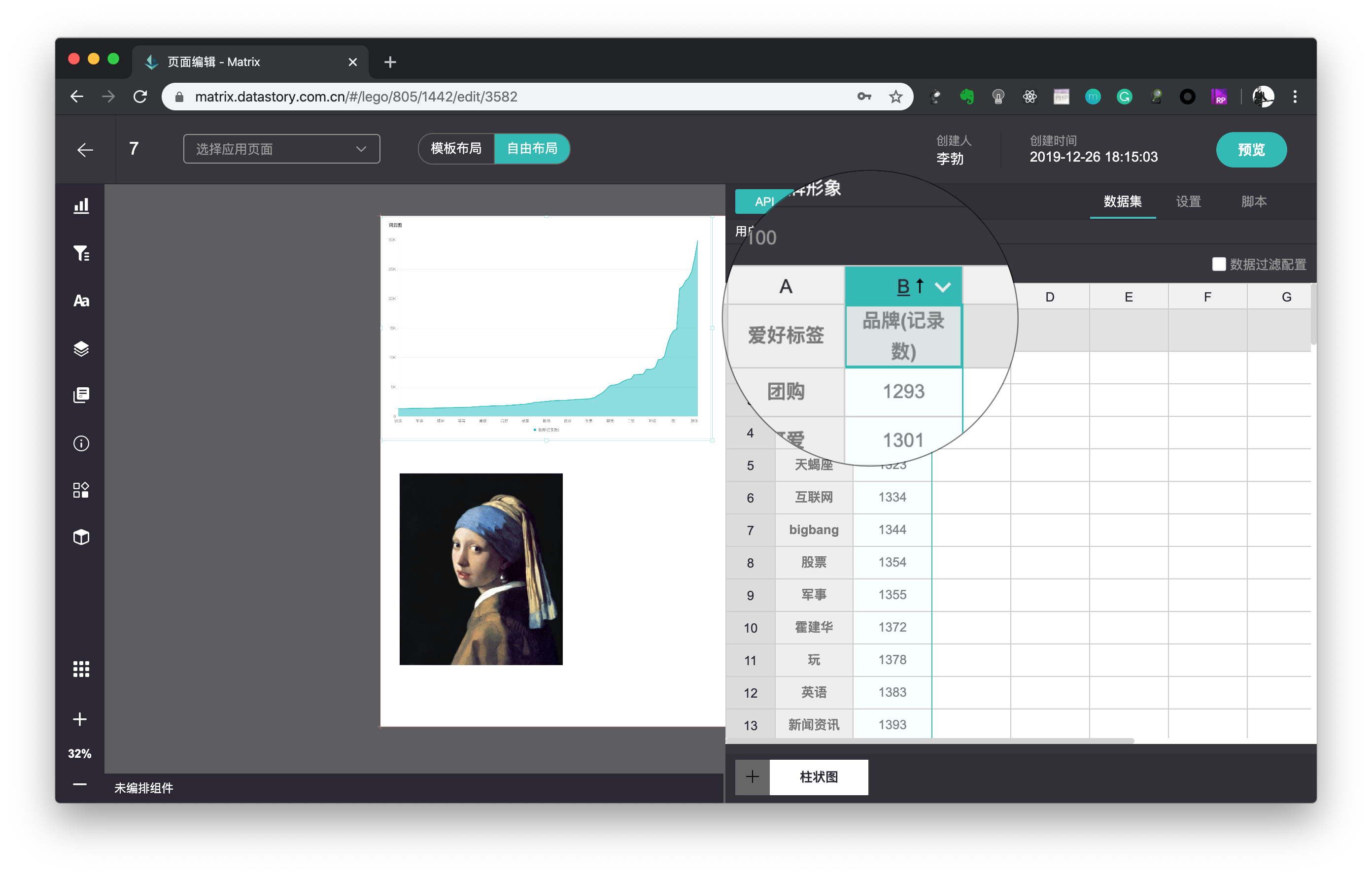
数据集列标触发排序
点击数据集中的顶部列标(列标一般用大写字母来表示),可以触发排序。如图通过点击B列的列标,使得数据集排序变为了从小到大的排列,可视化的面积图也随之变化(面积图的默认排序方式是从大道小)。
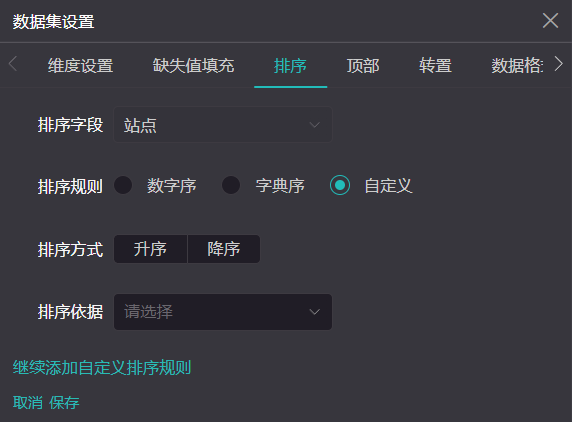
一般的排序方法就是数字排序法和字典排序法,但在部分场景下,例如上文中举的例子——对“一线城市”、“二线城市”等字符串排序,则无法实现。所以我们在数据集设置中引入了个性化排序的方法,可以由用户自定义排序规则。
数据集设置排序
点击数据集tab下的“小扳手”图标,可以找到排序tab。除了数字排序法和字典排序法,还可以选择自定义排序。 详细内容请看《数据集设置》——排序 https://open.datastory.com.cn/document/docs/5566
别名设置
有时,数据的值并没有进行语义化处理。例如为了优化存储空间和检索效率,在记录性别的时候可能把男性、女性记录为1和0,或者把一、二、三、四线城市、港澳台、海外分别记录为1、2、3、4、5、6;
这类数据在可视化的时候很容易给阅读者造成困难。方舟数说方舟提供了别名设置的功能。
接入数据集设置后,找到“维度设置”的选项,你可以选择对行维度(列头)或列维度(行头)设置别名。按照规范写入一段json,方舟就会按照该定义显示数据。
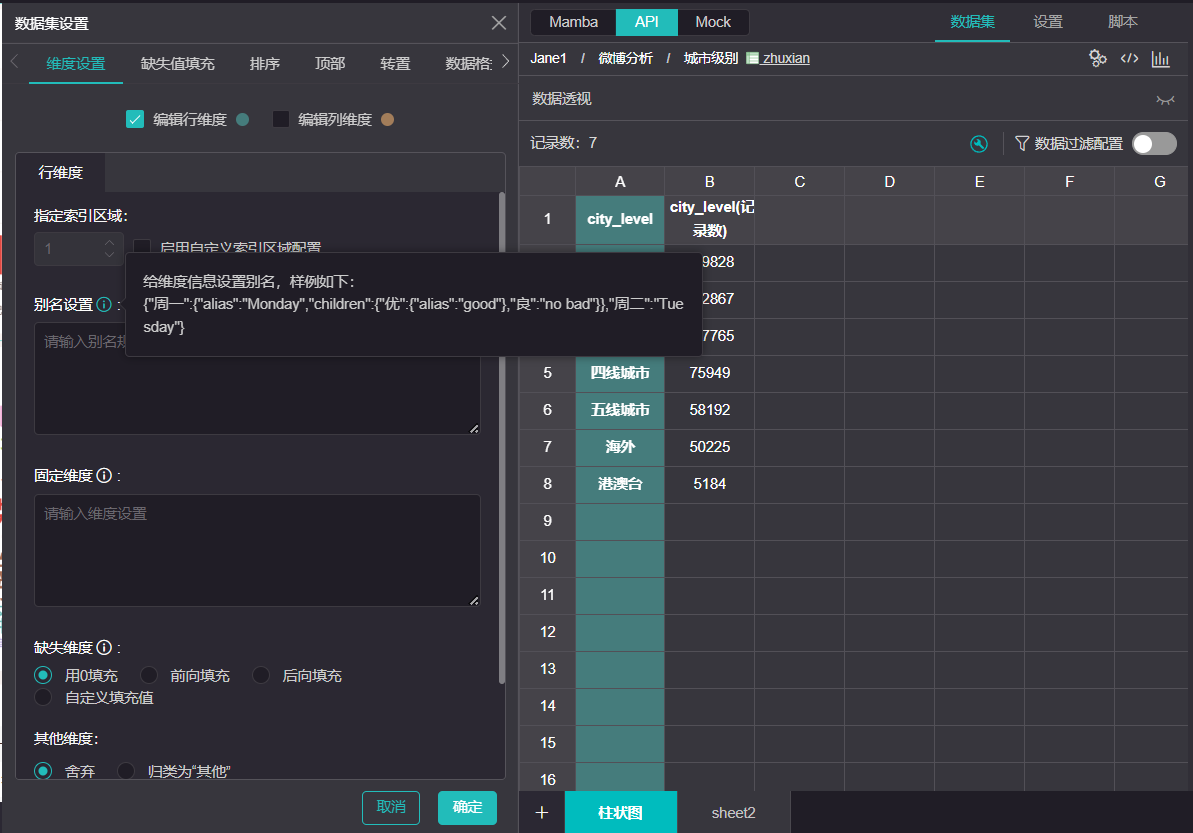
设置别名时用JSON对象,如
{
"0" : "女",
"1" : "男"
}或
{
"0" : {"alias":"女"},
"1" : {"alias":"男"}
}如果索引是多层嵌套的,设置别名也支持在嵌套的场景下执行,如
{
"1" : {
"alias" : "周一",
"children":
{
"0" : "女",
"1" : "男"
}
},
"2" : {
"alias" : "周二",
"children":
{
"0" : "女",
"1" : "男"
}
}
}重建索引
重建索引功能提供了一个方法,该可以使得数据集的索引结构总是符合期待——多余的数据会被清除或归类,缺失的数据会被填充,并且数据的排序规则会被规范。
如果你是一个习惯用python做数据分析的分析师,你可以把重建索引功能对应到pandas.DataFrame 中的 reindex()函数,他们在设计思路和能力上是一致的。
我们在前文第一个项目/让应用更完美/处理长尾中已经介绍过重建索引方法。
数据过滤脚本
有时候,我们需要对数据集进行更加深入的再加工,例如对数据进行log函数转换、z-score标准化,或者我们仅仅是想在可视化环节剔除含有某些特殊符号的数据。这时就可以使用数说方舟的数据过滤功能。
数据过滤功能允许用户用JavaScript语言定义一个数据处理防范,对数据集进行处理之后再返回给组件使用,而处理方式完全由脚本的编写者自主定义,大大增加了数据集再加工的灵活性。
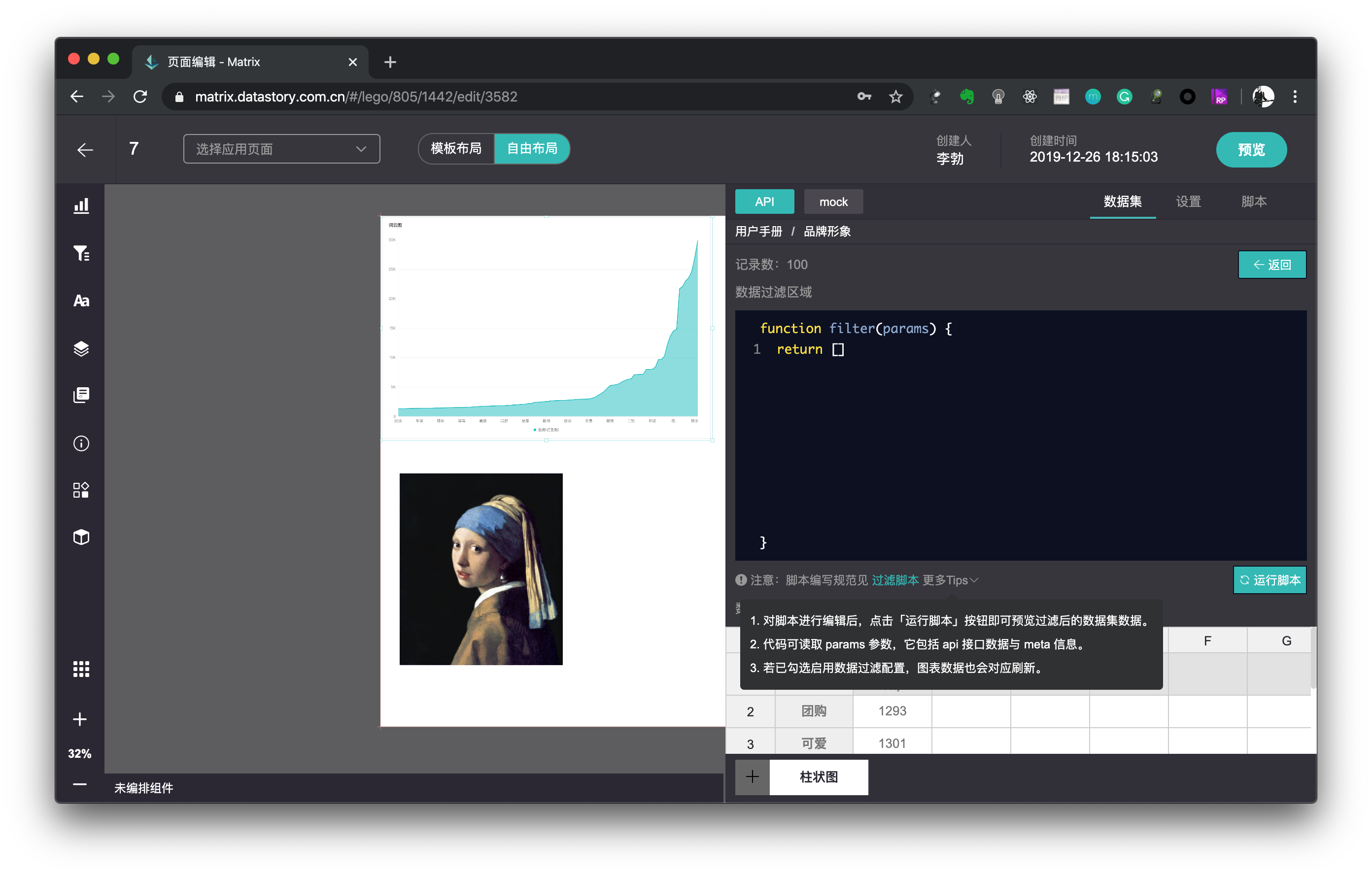
数据过滤脚本编写规范可以通过开发者文档/自定义脚本/过滤脚本了解
5.在数据集面板中下载数据
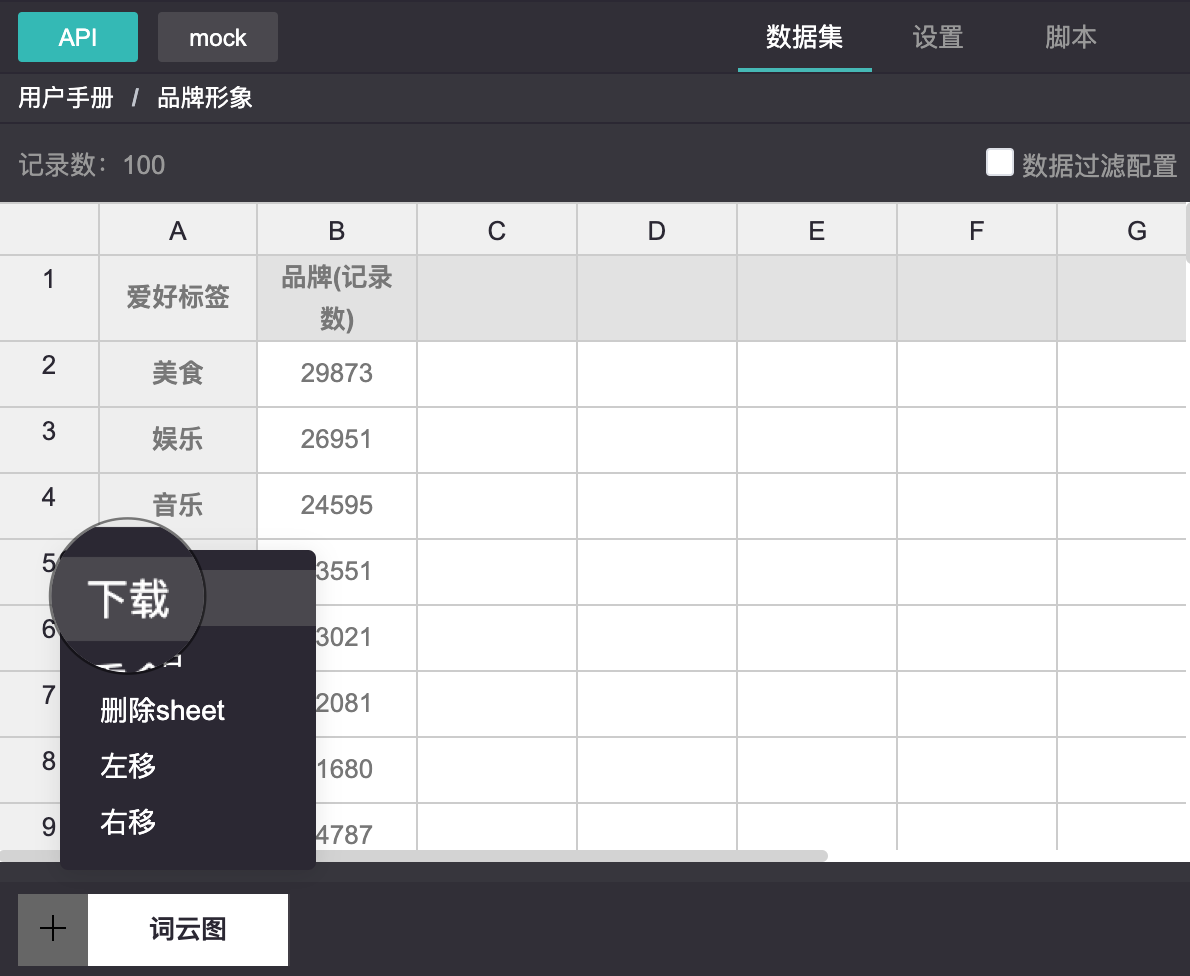
在数据集面板中下载数据
无论是mock数据还是API数据,数据集中每个sheet的数据都可以被下载为一个CSV文件,下载的CSV文件会被命名为[sheet名称].csv
下载的文件满足“所见即所得”的原则,即下载的数据文件中的数据与用户在数据集中看到的数据一致。严格来说符合以下规则:
- 仅下载当前数据集表格中显示的数据,如果数据有分页的情况,则此处只下载第一页数据;
- 无论是何种类型的接口数据,如果在数据集中配置了排序、重建索引、别名、数据过滤等规则,则规则的有效性会同样体现在下载的数据文件中;
- 下载的csv文件编码格式为UTF-8.
在组件中下载数据
- 图表组件中支持开启表格视图,开启之后,可以设置是否允许导出CSV文件。
- 表格组件、原文组件开启支持CSV下载后,允许下载数据。
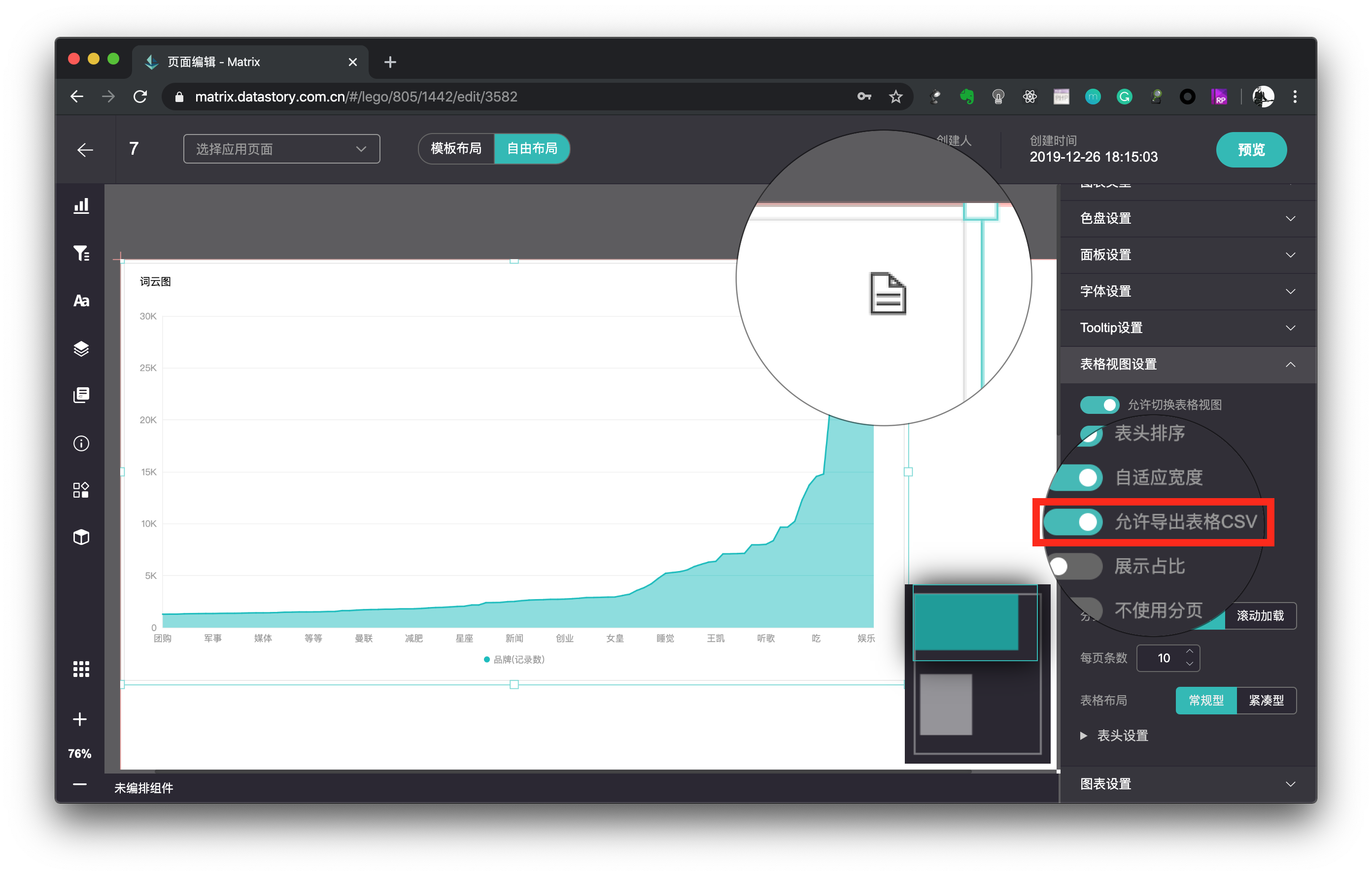
设置组件允许导出表格CSV之后,用户可以通过点击可视化组件的右上角,进入表格视图,并选择下载数据。


产品咨询
020-38061725

微信扫描二维码在线咨询