算子介绍
最新文档:https://doc.weixin.qq.com/doc/w3_AXIAVAbSAOg24PI7U3YT50JlTlCUT?scode=AK8ArQdJABEidVXkCxAXIAVAbSAOg
算子前置条件
目前基本上所有的算子都支持高级模块,高级模块下,系统会支持对数据进行前置条件。
前置条件:仅满足条件的数据会进入该算子的处理逻辑当中,该条件仅作用于当前配置的算子的处理过程,不会影响整个作业。
例如:高级码表标签算子配置了前置条件“id非空”,则仅有ID非空数据会执行打标签操作,但如果作业后续还有其他算子(如后面还有四则运算算子),而四则运算算子没有配置前置条件,则所有数据都会参与四则运算算子的处理。
数据处理算子
数据合并
行合并(数据追加)
支持对当前数据源以宽表追加多份数据源,对于表头,会在原有字段基础上增加列,对于数据,会以增加行的形式追加数据。本质上等价于union 操作
行合并配置过程中,可以支持用户手动选择多个数据源之间的映射字段。
举个例子 原有数据:
| ID | 订单金额 |
|---|---|
| 1 | 10 |
| 2 | 20 |
新增数据(需合并数据):
| ID | 订单金额 | 是否已付款 |
|---|---|---|
| 1 | 20 | Y |
| 3 | 20 | N |
合并后结果:
| ID | 订单金额 | 是否已付款 |
|---|---|---|
| 1 | 10 | |
| 2 | 20 | |
| 1 | 20 | Y |
| 3 | 20 | N |
这里需要注意,部分数据库在输出的时候,会根据ID或主键字段进行去重(如ES会去重) 最终得到输出的数据会是:
| ID | 订单金额 | 是否已付款 |
|---|---|---|
| 1 | 10 | |
| 2 | 20 | |
| 3 | 20 | N |
同ID会去重,但具体保留那条,是随机的(取决于输出执行的顺序,无法预测)
列合并(字段追加)
字段追加用于多份数据源需要根据某一字段进行关联的场景,等价于sql里面的join操作,常用于根据一些字段匹配后来追加新列
列合并配置过程中,需要指定一个多份数据源公共的可关联字段,并且设置其他数据源的保留字段(该字段会输出)。多个数据源合并时,同名列默认读取靠左的数据源。
如果出现多份数据源可关联字段不一致,则需要执行多个任务。
以下解释几个名词:
追加字段:是指两份数据共有的,可以作为关联的字段(如表A有订单ID、订单金额;表B有订单ID,下单用户),那么订单ID就是可以用来作为追加字段的共有字段
保留字段:是指关联后需要新增的列(如上例,需要把表B的下单用户追加)
链接方式:
①左连接
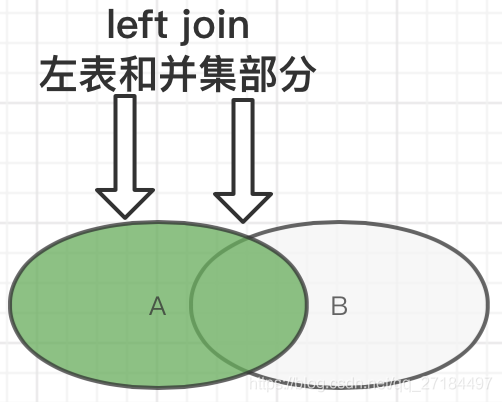
②左连接小表:和左连接一致,但如果B表数据量很少,用这个可以大幅提升性能,什么较小(数据量少于5W)
③全连接
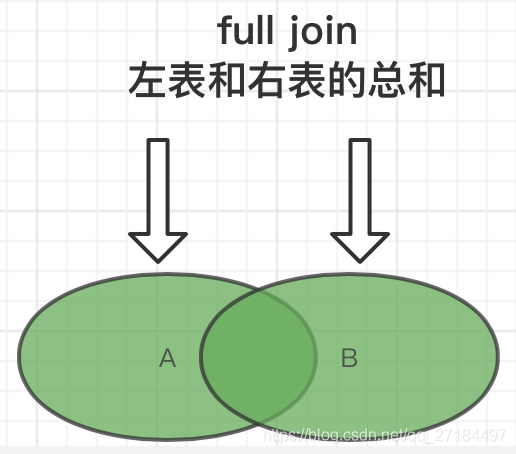
④右链接
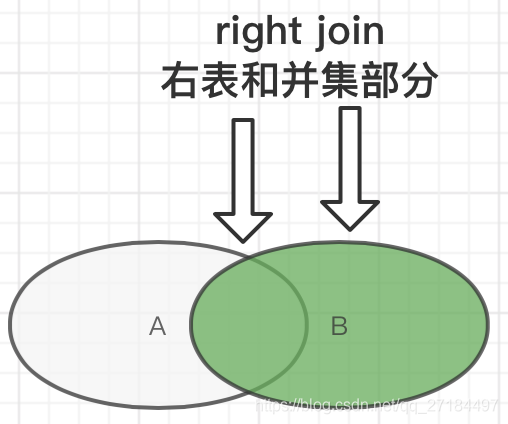
⑤内连接

举个例子:
例如有表A——订单表,表B——订单用户表
订单表A:
| 订单ID | 订单金额 |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 4 | 40 |
订单用户表B:
| 订单ID | 订单用户 |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
在配置追加字段(订单ID),保留字段(订单用户)条件下,在不同链接情况下他的返回分别为:
左连接&左连接小表:
| 订单ID | 订单金额 | 订单用户 |
|---|---|---|
| 1 | 10 | 张三 |
| 2 | 20 | 李四 |
| 4 | 40 |
内连接:
| 订单ID | 订单金额 | 订单用户 |
|---|---|---|
| 1 | 10 | 张三 |
| 2 | 20 | 李四 |
右连接:
| 订单ID | 订单金额 | 订单用户 |
|---|---|---|
| 1 | 10 | 张三 |
| 2 | 20 | 李四 |
| 3 | 王五 |
全连接:
| 订单ID | 订单金额 | 订单用户 |
|---|---|---|
| 1 | 10 | 张三 |
| 2 | 20 | 李四 |
| 3 | 王五 | |
| 4 | 40 |
去重
指定某个或多个字段拼成逻辑上的唯一字段,数据按该字段去重,删除重复数据,不生成新字段。
适用场景:需要单独对某个字段进行去重的时候(系统默认对内容进行去重)。
举例:选择字段1标题,再选择字段2url,确认,即表示对标题和url均一样的数据进行删除去重。
系统支持选择去重模式,随机、根据数据源其他字段取最大值、取最小值。
过滤
支持对数据进行过滤。过滤原理为,某条数据的某个字段匹配中用户设定的过滤条件,该条数据就会被过滤掉。不同数据类型的数据对应不同的匹配关系。匹配关系为包含/不包含时,过滤词支持用|表示或,用+表示且关系。 过滤后数据需要输出到一个新的数据源或者文件,否则直接写回原始数据的情况会出现数据没有变化的情况(因为写回原始数据不是清空后写入,而是追加/覆盖,原有重复数据不会被删除)
替换
对单个字段进行处理替换处理,将其中的某个词语替换成另外一个,不生成新字段。
适用场景:当需要修改具体某个词语时。
举例:查找字段选择内容,查找规则包含,查找内容为inter,替换为INTER。最终导出内容里inter被替换成了INTER
合并字段
对数据源多个字段进行合并操作,输出一个新字段
输出支持输出为长文本或短文本,支持合并分割符。类似concatenate操作。
数据质检
数据质检支持对单个数据源的字段进行精准的校验,常见如销售额是否非负数,ID是否非空等场景。
质检规则由一组条件组成,每个条件由字段、逻辑表达式、值组成(如销售额,大于,0);多个条件之间支持布尔表达式(条件1 或条件2)
系统会产生一个检测报告文件,文件里面包括质检检测概览和异常数据两部分组成。(每组条件都会产生一个独立的异常数据收集文件)
针对异常数据输出,用户可以自由选择输出的字段、可以选择压缩。
关键词提取句子
支持用户对文本字段根据一定的关键词规则抽取对应句子,配置参数说明如下:
分析字段:需要被提取的内容字段,一般为长本文字段,如内容、正文
表达式:提取的关键词规则,可以读取数据里面某个字段,也可以支持手动输入,支持|或者+等复杂表达式
字段类型:可选择输出为文本或者长文本
额外说明:分句逻辑基于正则,对应规则为[.?!。?!;…]|( *//@.+ +)
自发内容抽取
针对采集回来的微博内容,抽取用户自己发表的内容,生成1个新字段。
适用场景:需要单独对用户自己发的内容做处理时。
举例:微博内容数据为“我也喜欢吃苹果,哈哈哈//@易烊千玺:我喜欢吃苹果”,提取字段选择“内容”,结果会将//@前面的“我也喜欢吃苹果,哈哈哈”抽取出来存到内容_自发内容里。
聚合
聚合算子一般用于数据统计,可理解为sql里面的groupby,可支持某一些分析维度、指标进行agg类统计(目前系统支持求和、最大值、最小值、count、求平均),对应参数说明如下:
聚合维度:需要统计的维度(如站点、品牌)
聚合处理:需要统计的指标以及统计方法(如销售额,求和),输入后,需点击”+“按钮确认。聚合处理可支持配置多个配置
输出信息:数据的输出方式,支持ES\关系型数据库\追加\系统默认
值得注意的是,由于此算子输出存在降维情况(可理解输出的数据结构会发生变化、且数据量都会存在大幅减少的情况),仅支持单独输出。
高级码表标签
支持将打标签规则放到一个Excel里(此处叫做码表),批量对数据源中的若干个字段进行匹配,如果命中,则打上对应的标签。(可理解为SQL中的casewhen)。
码表制作介绍:
码表规则可分成正则表达式、平台表达式两大类,码表每列的规则仅可使用其中一种。如果混用可能会导致最终标签错误。由于正则是标准的表达式,参考正则规则即可,下文主要介绍平台表达式。
1.平台表达式:使用()|+!运算符,其中()为优先运算、|表示或关系、+表示且关系、!表示取反,允许单独使用,也允许组合使用,默认且关系优先级高于或关系。
- 对于类似 A+B|C+D+E|...|X+Y+Z 的表达式,会默认提升+的优先级,即等效于 (A+B)|(C+D+E)|...|(X+Y+Z)
- 对上情况,如果对语法优先级不确定或有特殊需求,可以多使用括号指定优先级,如:A|B+(C|D)|E 是有歧义的,需要用户按自己需要写成:(A|B) + ((C|D)|E) 或 \A| (B+(C|D)) |E
此外平台表达式需要注意转义符的使用,例如需要表达”1+手机",码表需要写成1\\+手机.平台通用的转移符号
注意转义的时候,要用两个\,如: Sony\\(ZX300\\) 。双引号除外。总结需要转义的字符:
| 需转义的字符 | 转义后 |
|---|---|
| + | \\+ |
| | | \\| |
| ! | \\! |
| ( | \\( |
| ) | \\) |
| " | \" |
码表匹配条件:码表填写的规则需要与匹配条件对应,否则将不会打上标签,对应关系如下图
| 码表填写规范 匹配条件 | 单个关键词 | 仅使用\ | 分隔 | 仅使用+ | ()\ | +组合 |
|---|---|---|---|---|---|---|
| 等于任意值/ 不等于任意值 | √ | √ | x | x | ||
| 包含/不包含 | √ | √ | √ | √ | ||
| 以上之外的匹配条件 | √ | x | x | x | ||
| eg: | A | A|B|C | A+B | A+ (B|C) |
l 使用逻辑:支持将复杂需求拆分成多条简单规则,再将简单规则用and or 组合,详情见后续例子。
l 嵌套字段:支持生成多个标签,并且标签可嵌套存储(当多个标签需要有一一对应关系时,需要用嵌套存储)
适用场景:需要批量打标签,或者需要多个字段同时满足多种条件等复杂逻辑,或者需要生成多级标签,或者需要生成多级嵌套标签字段
举例:
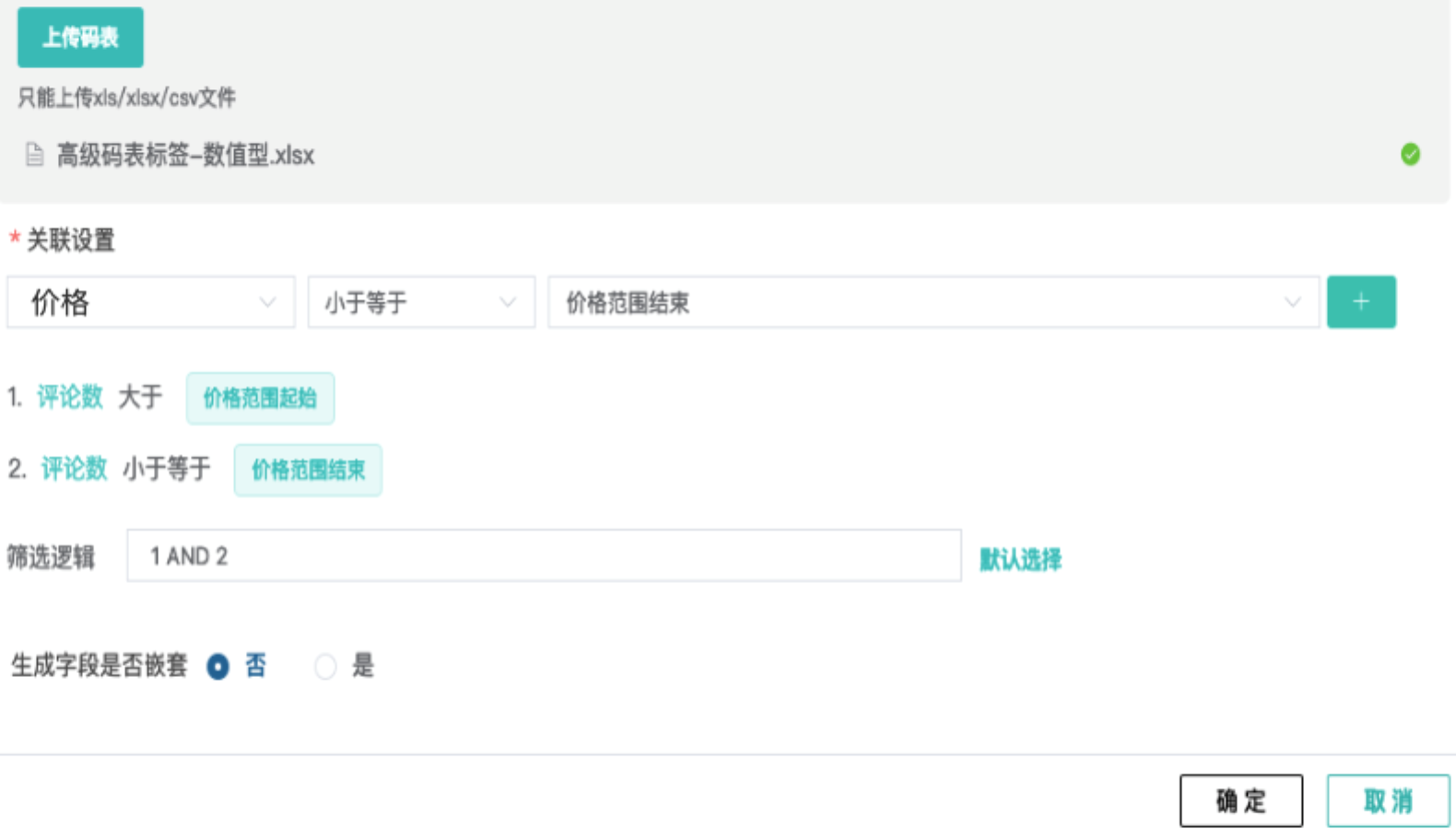
- 需要对数值类型的数据打标签
需求:对价格分类,0<价格<=2000的为低等消费、2000<价格<=5000的为中等消费、等5000<价格的为高等消费
1)码表整理为:
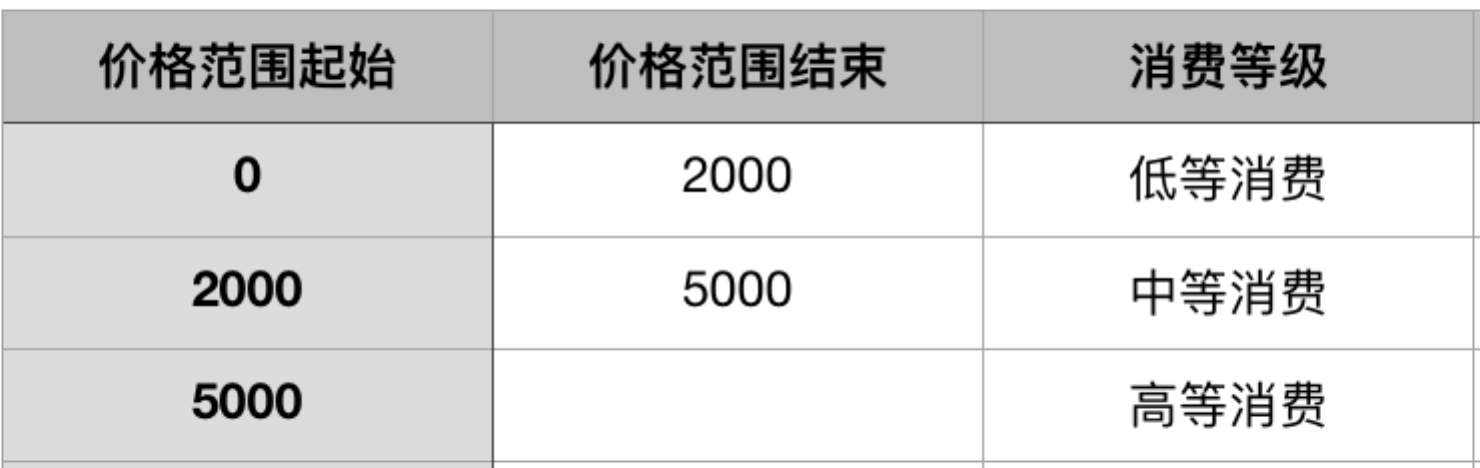
注意:对于数值类型的数据,码表里需填写数字。
2)上传码表,第一个下拉框为数据源字段,选择需要处理的字段“价格”(价格为数值类型),如下图所示,先配置第一条细分规则“价格大于价格范围起始”,添加后再配置第二条细分规则“价格小于价格范围结束”,注意码表里没有被选择使用的字段,会默认为新生成的标签字段,此处“消费等级”为标签字段。因为该需求的逻辑是要同时满足两条细分规则,所以使用逻辑设置为1 and 2。
- 需要对时间类型的数据打标签
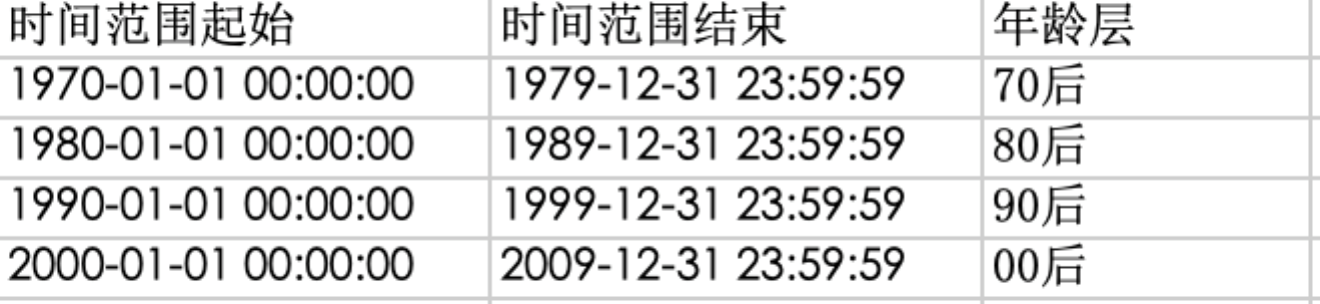
需求:根据出生日期,找出70后、80后、90后、00后的数据打上标签
1)码表整理为:
注意:对于时间类型,支持日期格式(yyyy-MM-dd HH:mm:ss)。
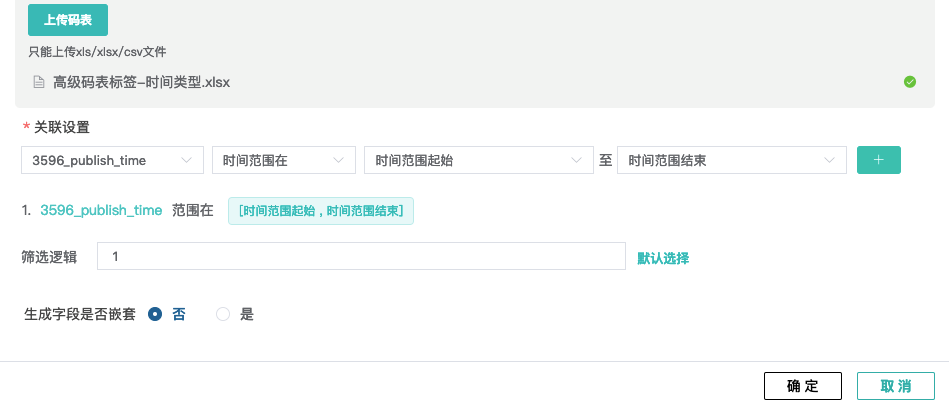
2)上传码表,第一个下拉框 “出生日期”(为时间类型),如下图所示,配置规则为“时间范围在时间范围起始至时间范围结束”,此处“年龄层”为要新生成的标签字段。逻辑设置为1。
- 需要对文本类型的数据打标签
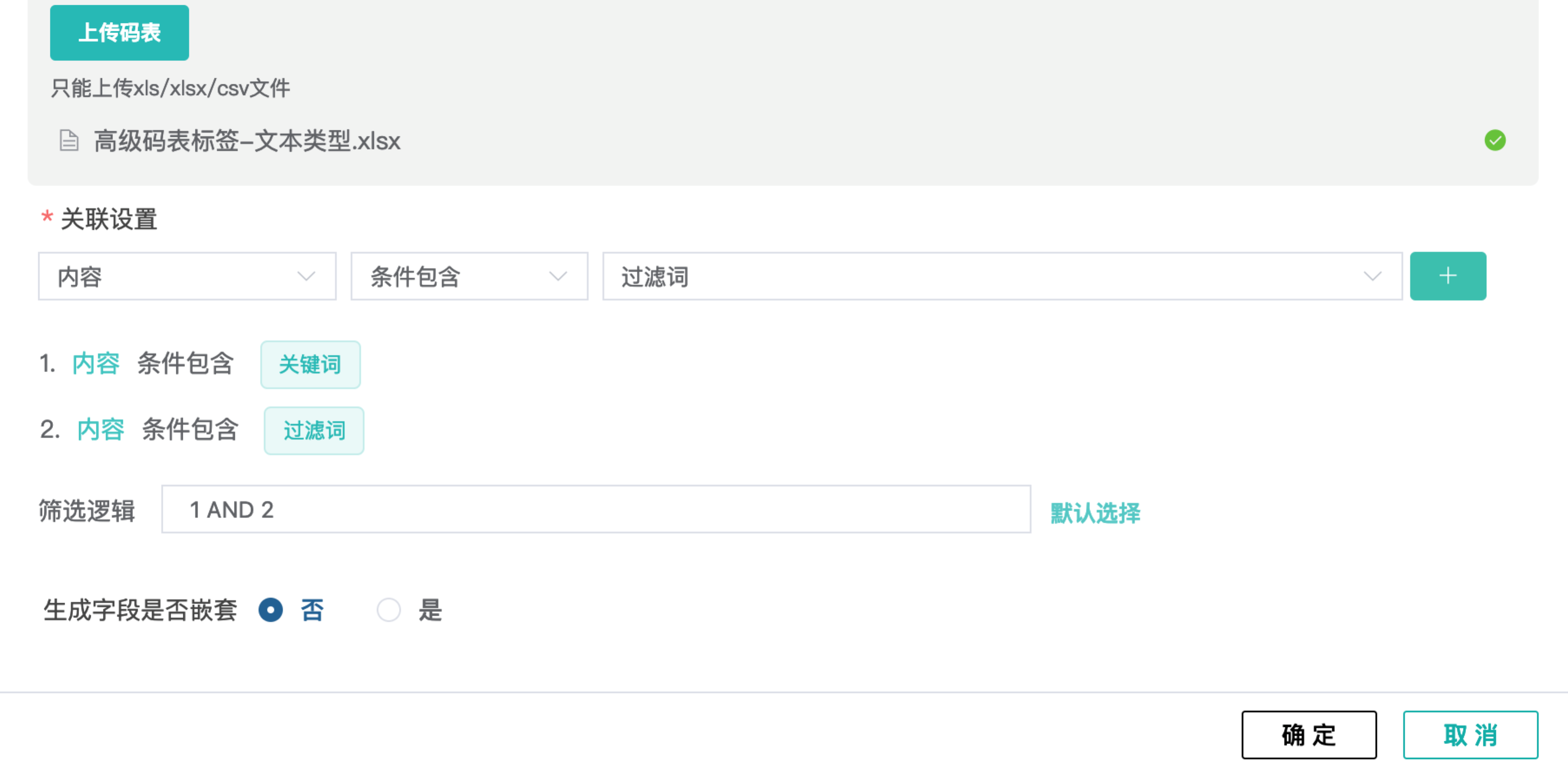
需求1:对内容按关键词过滤词打声量组成标签,声量组成包括剧情、投票、造型、台词、广告植入,每个声量标签对应各自的关键词和过滤词,见下图码表
1)码表
备注:
女神+(顾遥|罗玥) 表示内容同时提到女神和顾遥,或者同时提到女神和罗玥,即拆解后为女神+顾遥|女神+罗玥。
发起+投票|发起了+投票 表示内容同时提到发起和投票,或者同时提到发起了和投票。
搭配|服装|衣服|造型|发型 表示内容提到搭配,或者服饰,或者衣服,或者造型,或者发型。
!(台词功底) 表示内容没有提到“台词功底”。
!(没有发起+投票) 表示内容没有提到“没有发起”,或者没有提到“投票”。
!(伊利joyday|伊利JoyDay) 表示内容没有提到“伊利joyday”,且没有提到“伊利JoyDay”。

作业基础配置介绍
1)上传码表,第一个下拉框 “内容”(为文本类型),如下图所示,配置规则为“内容包含过滤词”,添加为1,再配置“内容包含过滤词”,添加为2,此处由于码表里的过滤词有用!取反,所以用包含,如果没取反,则用不包含。此处“声量组成”为要新生成的标签字段。逻辑设置为1 and 2。
=注意:往往在真实场景中,需要用到多种类型的数据,此时只需要在码表里分别对每种类型的数据设置其对应的码表,然后在系统进行关联设置,最后通过使用逻辑and/or组合起来。
2)生成嵌套类型的标签字段
1) 码表

2) 上传码表,配置“内容包含关键词”。剩下的一级和二级会按从左到右的顺序生成嵌套标签,即一级标签和二级标签。设置嵌套字段的中英文,用于存储和显示,如下图所示。
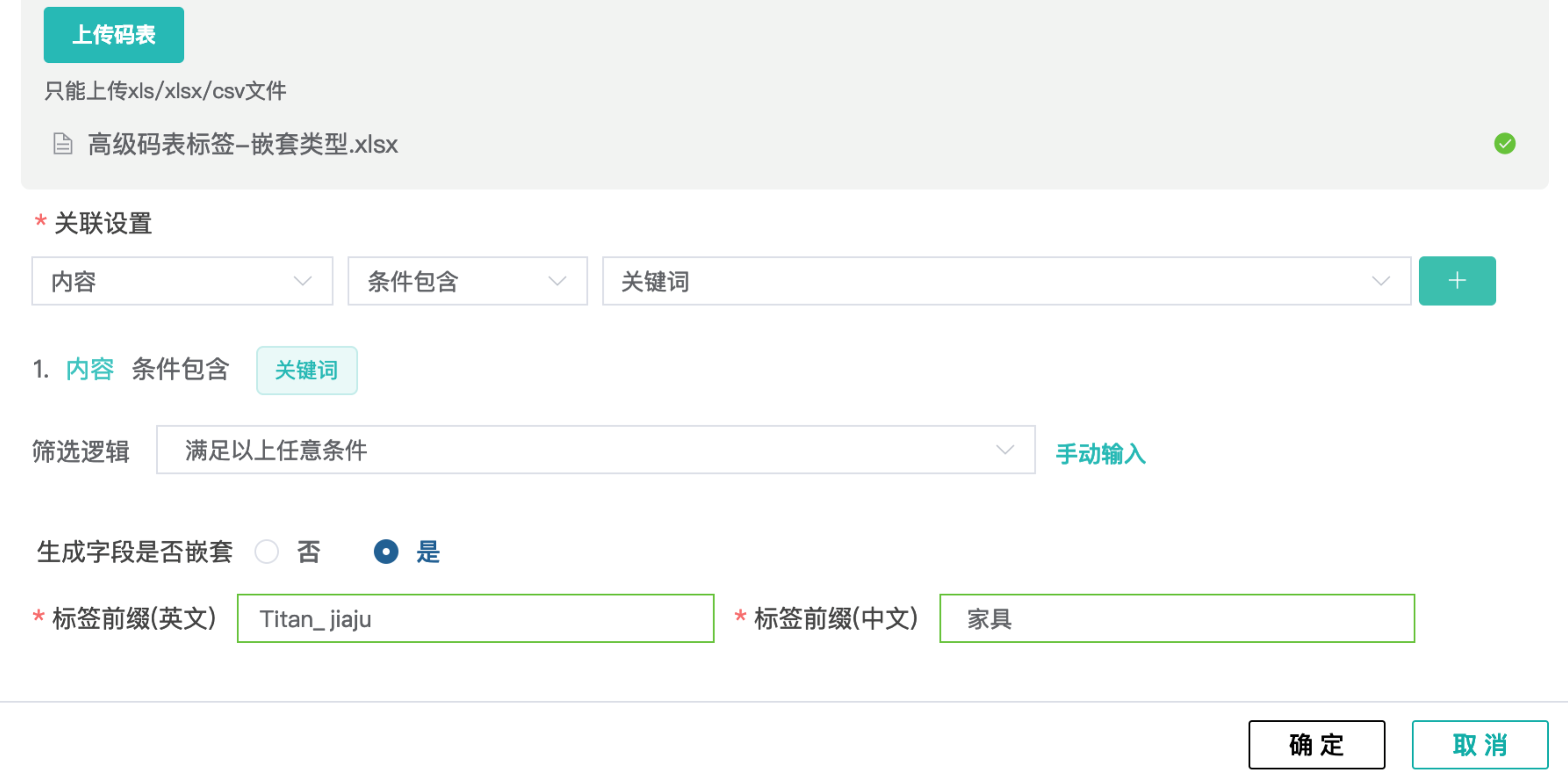
码表高级配置介绍
在码表标签功能中,有比较多高级使用的配置项,具体介绍如下:
1.区分大小写 是否要求码表规则和原文完全吻合,英文内容是否区分大小写
2.是否剔除表情 此配置实际上执行了正则表达式去移除原文的字符,有时可能会对其他规则造成影响。
3.是否截断 当被打标签的字段字符长度较长时,可能会对性能和任务时长造成很大影响,因此提供截断功能,仅扫描前N个字符。目前支持5000,10000,20000,不限制。
4.码表空值处理
当码表规则列某行为空的时候的判断机制,默认为跳过。如码表逻辑表达式为:(1 or 3) and 2,条件1匹配一个空的规则。根据配置,实际表达式会化简为:
跳过:3 AND2 ;恒为ture: 2 ; 恒为false: 3 and 2
5.是否短路 系统默认当满足规则时,就会停止对该行规则的继续匹配(此操作称为短路),因此可能出现关键词收集不全的情况,如需收集全部关键词,需要打开短路。但打开短路会导致任务性能大幅下降。
6.仅输出首个结果 默认情况下,系统会根据码表输出标签,每条数据的标签可能存在多个,因此默认会输出数组字段。开启此配置后,系统会按码表先后顺序,默认输出第一个标签,并设置字段类型为文本。
7.码表诊断行数 用于打印数据和具体某行码表规则的匹配日志。用户在输入框中输入需要校验的码表行数(不算表头的第一行为1)。
8.是否收集关键词 系统支持对规则匹配(包含、等于等条件)的词语进行收集,生成一个新字段,字段的值是该条数据命中了码表里的什么关键词,规则不匹配(不包含、过滤)的词语收集,为过滤词字段。beta功能,作为码表打标签的辅助。
- 全部收集:全部数据记录进行收集
- 去重收集:针对关键词去重。如数据匹配中关键词两次,也会显示一个
- 收集并统计频率:收集关键词的基础数,增加频率计算。输出样式如下

9.编码类型 上传的码表,系统会自动推断csv文件的编码,但可能存在不准的情况。因此支持手动制定UTF-8或gb2312
10.句内包含 系统提供的一种更高级的精准匹配方式,系统会根据分句标点符号,对待匹配字段进行切割,根据用户的匹配,严格判断在N句话内满足规则。如最终分割出来的句子超过15句,系统会自动会进行句子的合并,最终合并成15段待匹配文本。
- 用户输入2,则表示头2行的范围内匹配中,即会打上标签。
- 句内包含条件不填写默认距离默认为1 句。
- 句的判断判断符号为 .?!。?!;... 或者 //@
- 支持指定跨句数,即分句后,要求连续N句话组成的句子满足条件。 如:文本 A。B。C,跨句数N=2,则会分别判断 A。B和B。C是否满足表达式条件。
11.生成字段是否嵌套
简单来说,嵌套字段保存了多个字段值之间的映射关系。比如“苹果”与“iPhone13”,“华为”与“Mate20 Pro”。
打的标签比较多、比较复杂时,比如要打一级、二级、三级品类,即字段(表头)有层级,此时可以使用生成嵌套字段功能,保留字段值之间就需要有映射关系,来保证查询/统计结果的精确。
生成嵌套字段后,在分析表中针对嵌套字段做行内筛选即可用于分析。
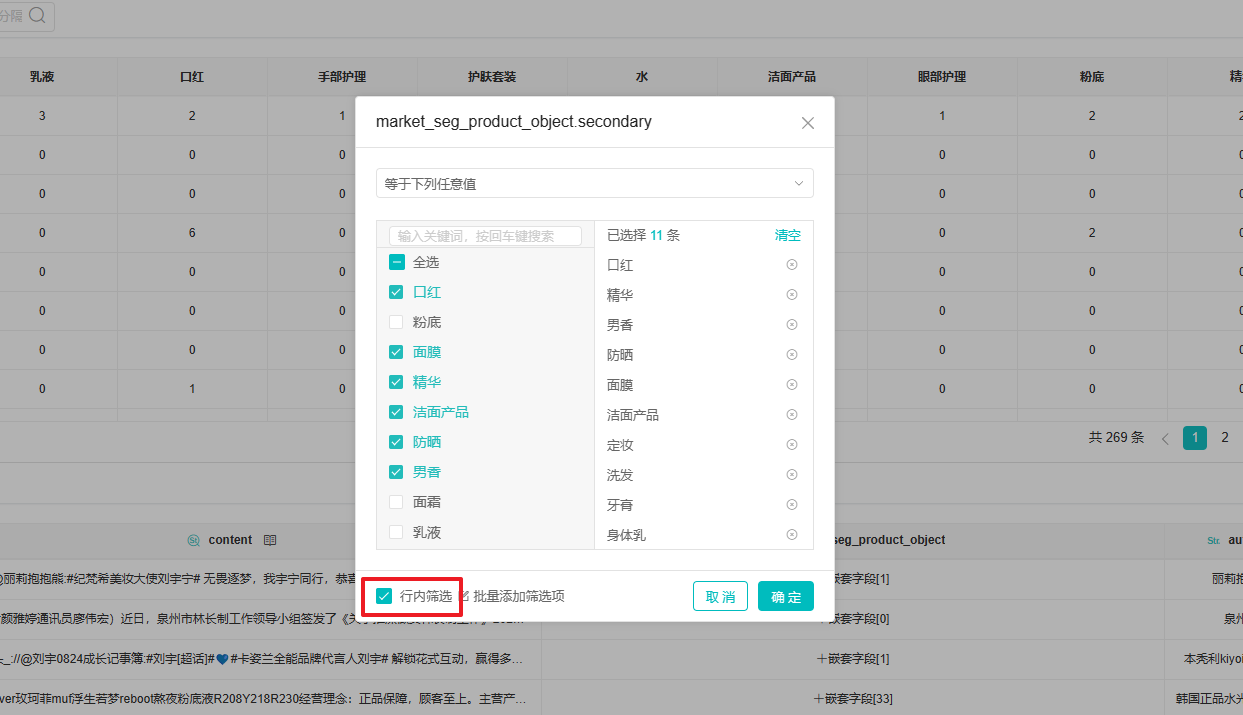
注意:如果要把数据导出到 excel 里去分析,会将嵌套字段拆分平铺展示。此时字段值之间的关联关系还是会丢失,需要考虑增加一个合并的字段(即直接把含层级/关联关系的标签合起来),值类似是”产品属性——味道好“。
举例
- 数据:ID=“A”,内容=“亲测华为的Mate20 Pro比苹果的iPhoneX性价比好太多了,美观实用拍照好,不服来PK!”
- 处理:用品牌码表打品牌标签,用机型码表打机型标签。
- 需求:查询华为品牌的各机型声量分布
方式一
不用嵌套字段,打标签结果如下(用竖线“|”代表数组分隔)
| ID | 内容 | 品牌 | 机型 | ||
|---|---|---|---|---|---|
| A | 亲测...不服来PK! | 华为 | 苹果 | Mate20 Pro | iPhoneX |
按照需求,SQL 语句就是:select 机型,count(*) as 数量 from t1 where 品牌=‘华为’ group by 机型; 结果如下:
| 机型 | 数量 |
|---|---|
| Mate20 Pro | 1 |
| iPhoneX | 1 |
条件为 品牌=‘华为’,却查出了“iPhoneX”。显然不对。
方式二
用嵌套字段,打标签结果如下。(注意,还是一条数据)

按照需求,SQL语句就是:select 品牌机型.机型,count(*) as 数量 from t1 where 品牌机型.品牌=‘华为’ group by 品牌机型.机型; 结果如下:
| 品牌机型.机型 | 数量 |
|---|---|
| Mate20 Pro | 1 |
显然,结果比方式一更加准确。
*在码表配置面板选择“高级”tab时,可对码表本身进行筛选,用于作业只需要用到一个码表里的部分规则的情况。
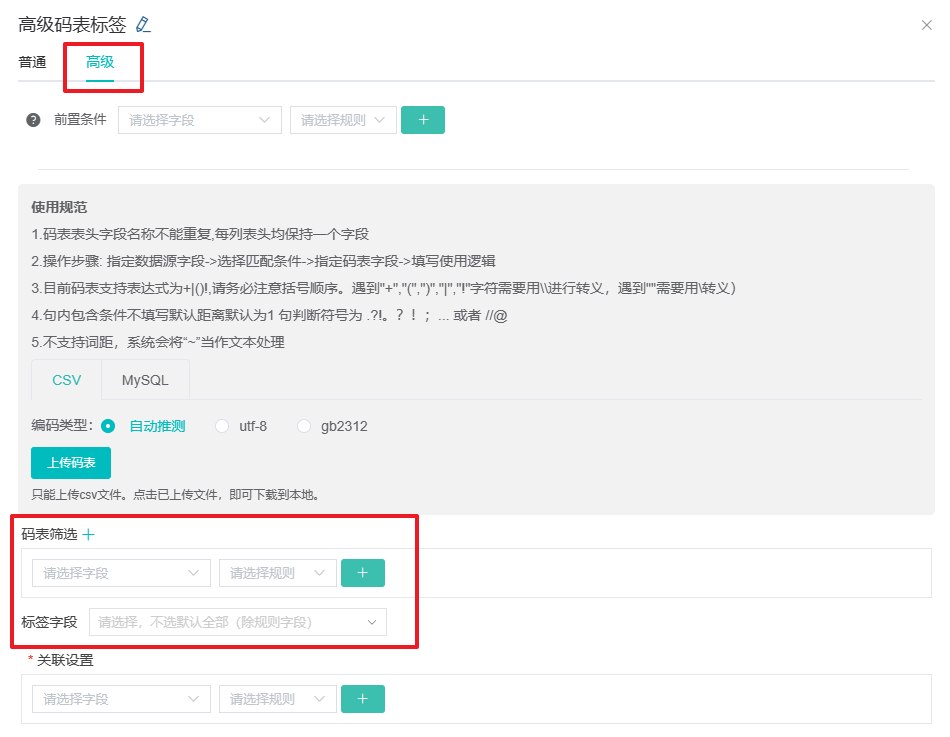
即对码表进行行和列的筛选

普通码表标签
对单个字段进行打标签,允许设置多条打标签规则,即单条记录打多标签,用|间隔,生成1个新字段。
适用场景:需要对某个字段打上多个标签,且打标签的规则比较简单。
举例:标签字段选择内容,输入新字段名称,匹配条件选择包含,关键词为红色,打标签为“红色”,点击“添加”,若有多条打标签规则,则继续添加。
excel工具箱/四则运算
支持用户输入excel公式对原始数据的多列数据进行计算,并生成新字段。新字段的字段类型需手动指定。相关使用说明如下:
1.目前支持+-*/()等算术运算及excel函数,自动补全常用的函数,如IF/DATE/MATCH/LEN等。实际上所有函数均支持,只需按标准语法声明如 LEN(#{content}) 的格式即可。
2.声明字段时,请使用#{}包裹,例如#{view_nct}
3.所有的excel函数都是针对行的处理,所以类似统计标准差、SUM、AVERAGE等常用于列处理的函数无实际意义,建议不要做类似操作。
4.强烈建议不要做行列转置再上传等黑科技操作。
5.数据存在部分为空,需要声明默认值,否则不做处理。例如#{view_nct||0}
6.不需要在公式最前面输入”=“号
7.表达等于的意思,需要输入”==“,例如#{view_nct}==0,Excel算子里面的函数公式和Excel一样,如果是字符串需要使用双引号“” 标记
8.使用过程中,请注意规范使用英文括号,公式的声明应全部使用大写英文字母
json提取
基于jsonpath语法对json格式字段进行提取,将提取内容输出新内容,相关配置参数如下:
提取字段:需要提取的json原始字段
简单模式提取:
提取内容:允许用户输入json第一层的KEY进行提取,例如提取brand
高级模式提取:
提取内容:允许用户输入完整的jsonpath表达式提取,例如otherdate.brand
字段类型转换
读取数据源某列数据,并以此作为数据,输出一个自定义数据类型的新字段。相关配置说明如下:
字段:需要被转换的原始数据字段
转换类型:新字段的数据类型。可转换的字段类型根据原始的数据类型,存在一定的限制。
如果字段选中了一个日期类型的字段,系统会额外提供一个配置项,允许用户自己输入format函数转换日期格式。
算法类算子
详情请查阅:https://wiki.ds-int.cn/pages/viewpage.action?pageId=35390936&from_wecom=1
输出类算子
原始数据源
输出回原始数据源,即处理后的数据直接写回当前的数据源,但为安全起见,若数据源是本地上传的,或者有使用去重、过滤、替换中的任意一个算法,不支持写回原始数据。
FTP
支持用户定义FTP地址,数据将以文本形式推送到该FTP地址,文本包括CSV和Excel两种格式,由用户选择。FTP拼接条件为待补充
es
支持数据输出到新的ES集群,如果被输入的集群已存在,可使用追加功能。
举例:从左侧栏拖拽“ES”选项到中间空白的地方,系统会弹出框,用户输入数据源名、集群名称、索引名称、索引类型、ES节点,点击“测试链接”,当右上角弹出测试链接成功时方可确认。生成的数据源会在新建的集群看到,也能在工场的数据源模块看到,用于多次处理数据。注意,若该集群已存在,无法通过测试。
高级配置支持指定_id字段取值、支持字段前缀声明、支持DOC更新策略、支持清空后写入
关系型数据库
支持对MySQL、SQL sever、Oracle的数据源的输出,
高级配置支持清空后写入场景,支持制定主键、联合主键场景。
Mongodb
支持对Mongoldb数据源的写入输出
高级配置支持清空后写入场景。
hive
支持对hive数据源的写入输出
高级配置支持分区写入
文件
支持输出CSV、json、parquet、excel文件。选择parquet文件时,可以输出到腾讯云COS和阿里云OSS。超过5W条数据,建议使用CSV文件,避免内存溢出错误。 支持对文件压缩和加密。
追加
支持对已在平台的数据源再次追加数据。若是想对平台没有处理过,但是已有数据的ES集群追加数据,该追加功能依然支持。
适用场景:数据需要追加到已有数据的数据源里,两份数据源字段个数可不同、字段名称可不一致,但字段名一致的时候需要类型也一致。
ceph
支持输出到ceph,支持压缩和加密


产品咨询
020-38061725

微信扫描二维码在线咨询