入门知识
数据表的结构
简单数据表结构
数据表对应关系型数据库中的一个table(我们也可以类似地把关系型数据库的view理解为表)。在NoSQL数据库中,数据表的概念对应为collection或index.
假如有一个班级学生成绩表,分别记录了5位学生的的学号 姓名 语文成绩 数学成绩和体育成绩, 在关系型数据库中,可能会按照如下形式存储:
| id | name | language | math | physical |
|---|---|---|---|---|
| 20190001 | 王语嫣 | 100 | 98 | 59 |
| 20190002 | 段誉 | 98 | 50 | 90 |
| 20190003 | 虚竹 | 58 | 89 | 99 |
| 20190004 | 乔峰 | 100 | 90 | 99 |
| 20190005 | 木婉清 | 90 | 90 | 90 |
而在NoSQL中,存储同样的数据可能是这样的形态:
{
"id":20190001,
"name":"王语嫣",
"language":100,
"math":98,
"physical":59,
},
{
"id":20190002,
"name":"段誉",
"language":98,
"math":50,
"physical":90,
}
..."id"、"name"、"language"、"math"、"physical"是数据表的表头,也被称为schema,表头里面的每一个元素被称为一个字段。
每一个学号(id)对应了一条学生成绩记录,称为数据表的一条记录。
有嵌套的数据表结构
关系型数据库中,一个字段和一条记录可以唯一定义一条数据,但如果我们想要在一个表中记录一个学生的各科考试成绩以及授课老师等更多信息,一个字段可能会存放着另一张"数据表",我们称这样的字段为嵌套字段,嵌套字段在NoSQL数据库中常常会存在,例如下面数据表的record字段:
{
"id":20190001,
"name":"王语嫣",
"record":[
{
"subject":"语言",
"teacher":"李青萝",
"score":98,
},
{
"subject":"数学",
"teacher":"李青萝",
"score":97,
},
{
"subject":"体育",
"teacher":"慕容复",
"score":61,
}
]
},
{
"id":20190002,
"name":"段誉",
"score":[
{
"subject":"语言",
"teacher":"刀白凤",
"score":98,
},
{
"subject":"数学",
"teacher":"段正淳",
"score":50,
},
{
"subject":"体育",
"teacher":"段正淳",
"score":90,
}
]
}
...数说方舟有能力对简单数据表进行分析,也有能力对嵌套数据表进行分析。
记录与筛选
记录
对于关系型数据库的表,一条记录,即一行(row)数据。NoSQL语境下一条记录对应了一个文档(document)。方舟对数据进行筛选即获取特定的行或文档。下列三种情况,都是数据表的一条记录(从业务角度看,他们也表达同样的含义,即王语嫣同学的学习成绩):
| id | name | language | math | physical |
|---|---|---|---|---|
| 20190001 | 王语嫣 | 100 | 98 | 59 |
{
"id":20190001,
"name":"王语嫣",
"language":100,
"math":98,
"physical":59,
}{
"id":20190001,
"name":"王语嫣",
"record":[
{
"subject":"语言",
"teacher":"李青萝",
"score":98,
},
{
"subject":"数学",
"teacher":"李青萝",
"score":97,
},
{
"subject":"体育",
"teacher":"慕容复",
"score":61,
}
]
}字段
在数据表中,关系型数据库用“字段”来表达一列(column)数据,NoSQL的术语中用“字段”来表达一个数据域(field)。需要注意的是NoSQL中一个字段可能是嵌套类型,此时该字段会有下层的嵌套字段,如下面这条记录中,record 是一个字段,同时 subject、teacher、score 是其下层嵌套字段。
{
"id":20190001,
"name":"王语嫣",
"record":[
{
"subject":"语言",
"teacher":"李青萝",
"score":98,
},
{
"subject":"数学",
"teacher":"李青萝",
"score":97,
},
{
"subject":"体育",
"teacher":"慕容复",
"score":61,
}
]
}筛选
筛选 往往是分析的第一步,筛选的对象是 数据表 的 记录。所谓“筛选”,即按筛选条件获取数据源的特定记录。
筛选条件
对字段进行筛选,所筛选的是 满足某些字段的某些条件 的记录。现在针对上述数据表,可以给出这样的三条筛选条件:
- language得分在60分以上;
- math得分在75分以上;
- name不是乔峰;
这三条筛选条件都可以在数据筛选中发挥作用,但是仅有筛选条件还不够——如果有多条筛选条件时,筛选条件需要按照一定的筛选逻辑进行组合。
筛选逻辑
筛选逻辑有 且 或 非 优先运算 四项,分别用 and or ! () 表示。
如果我们按照如下的筛选逻辑来组合筛选条件:
language得分在60分以上 or math得分在75分以上 or name不是乔峰
得到的结果是
| id | name | language | math | physical |
|---|---|---|---|---|
| 20190001 | 王语嫣 | 100 | 98 | 59 |
| 20190002 | 段誉 | 98 | 50 | 90 |
| 20190003 | 虚竹 | 58 | 89 | 99 |
| 20190004 | 乔峰 | 100 | 90 | 99 |
| 20190005 | 木婉清 | 90 | 90 | 90 |
因为这里任何一个记录都能至少满足三个条件中的一个。但如果改一下筛选逻辑:
math得分在75分以上 and (language得分在60分以上 or name不是乔峰)
得到的结果是
| id | name | language | math | physical |
|---|---|---|---|---|
| 20190001 | 王语嫣 | 100 | 98 | 59 |
| 20190003 | 虚竹 | 58 | 89 | 99 |
| 20190004 | 乔峰 | 100 | 90 | 99 |
| 20190005 | 木婉清 | 90 | 90 | 90 |
数据透视
数据透视表是任何一个从事数据分析的专业人士都需要掌握的分析工具。
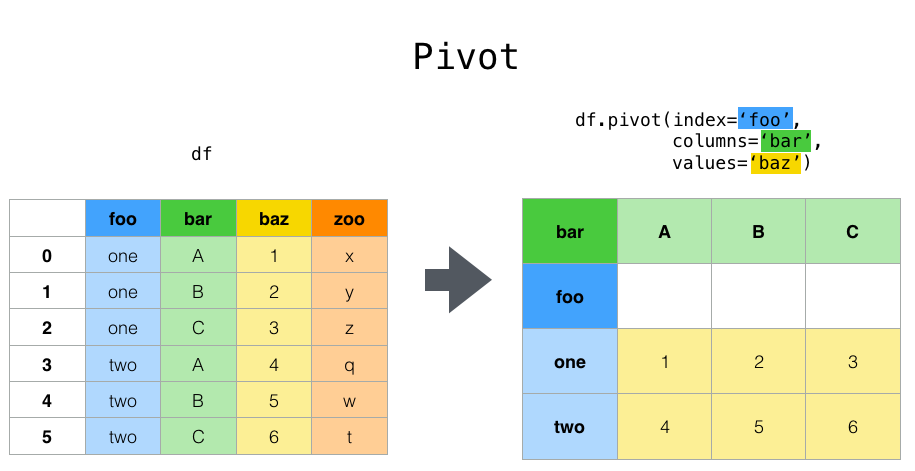 数据透视表英文叫“pivot table”,是伴随着计算机图形界面(GUI)的发展而出现的一种数据分析交互语言——1991年,Lotus Development在NeXT平台上发布了Lotus Improv,第一次实现了数据透视表的核心功能,允许用鼠标拖拉该改变分析视图(A tool that could help the user recognize these patterns would help to build advanced data models quickly. With Improv, users could define and store sets of categories, then change views by dragging category names with the mouse. This core functionality would provide the model for pivot tables).
数据透视表英文叫“pivot table”,是伴随着计算机图形界面(GUI)的发展而出现的一种数据分析交互语言——1991年,Lotus Development在NeXT平台上发布了Lotus Improv,第一次实现了数据透视表的核心功能,允许用鼠标拖拉该改变分析视图(A tool that could help the user recognize these patterns would help to build advanced data models quickly. With Improv, users could define and store sets of categories, then change views by dragging category names with the mouse. This core functionality would provide the model for pivot tables).
之后这种基于GUI的交互式分析方式在Macintosh上面有了软件实现,然后是Windows上的实现...
常见的数据透视表实现
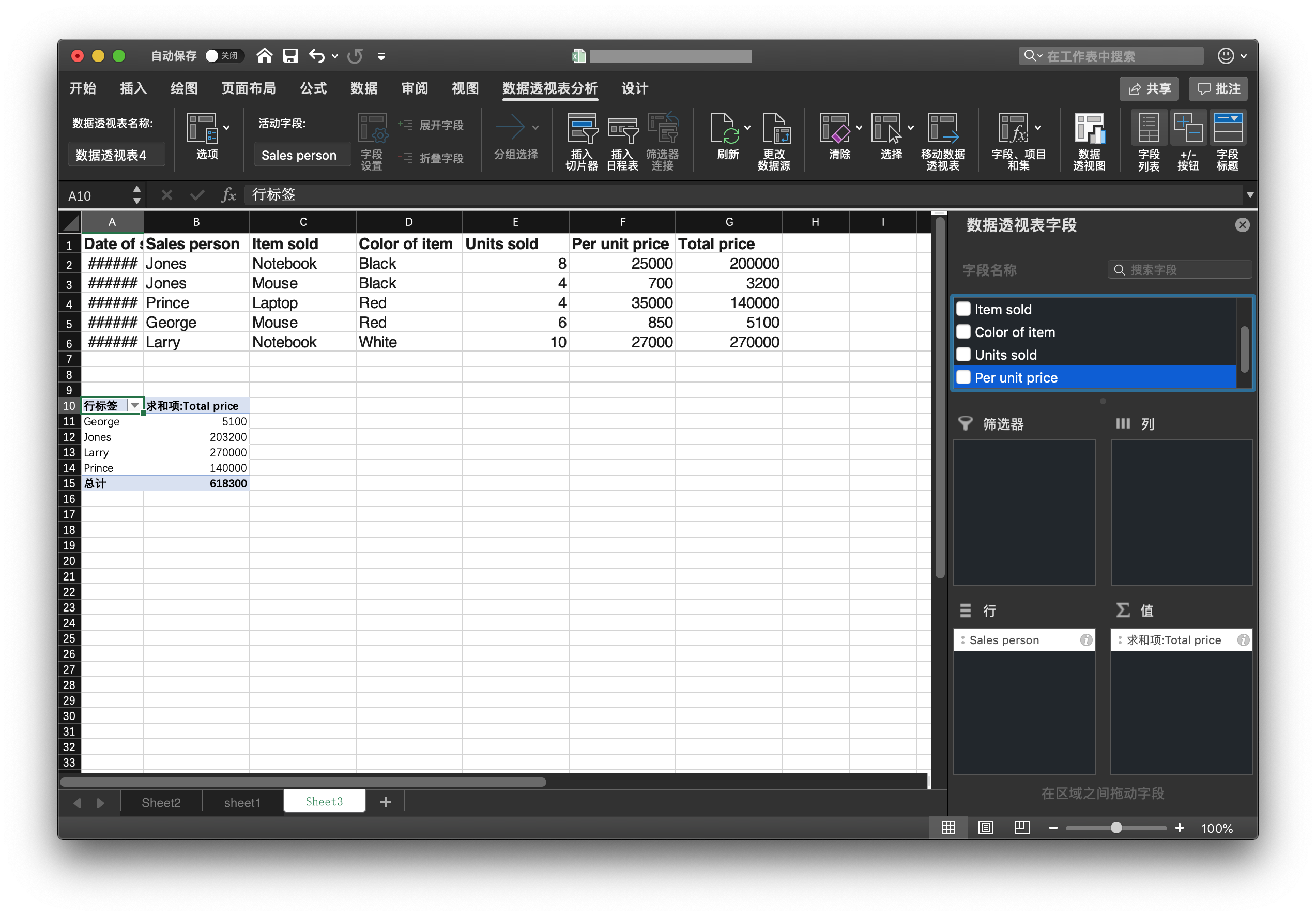
现在软件市场上可以见到的,最古老的,实现数据透视表的软件是微软的Excel。微软1994年在Excel中实现了这个功能,并在后续的版本中持续优化,直到今天数据透视表仍然是Excel的一个重要功能。
Excel中的数据透视表
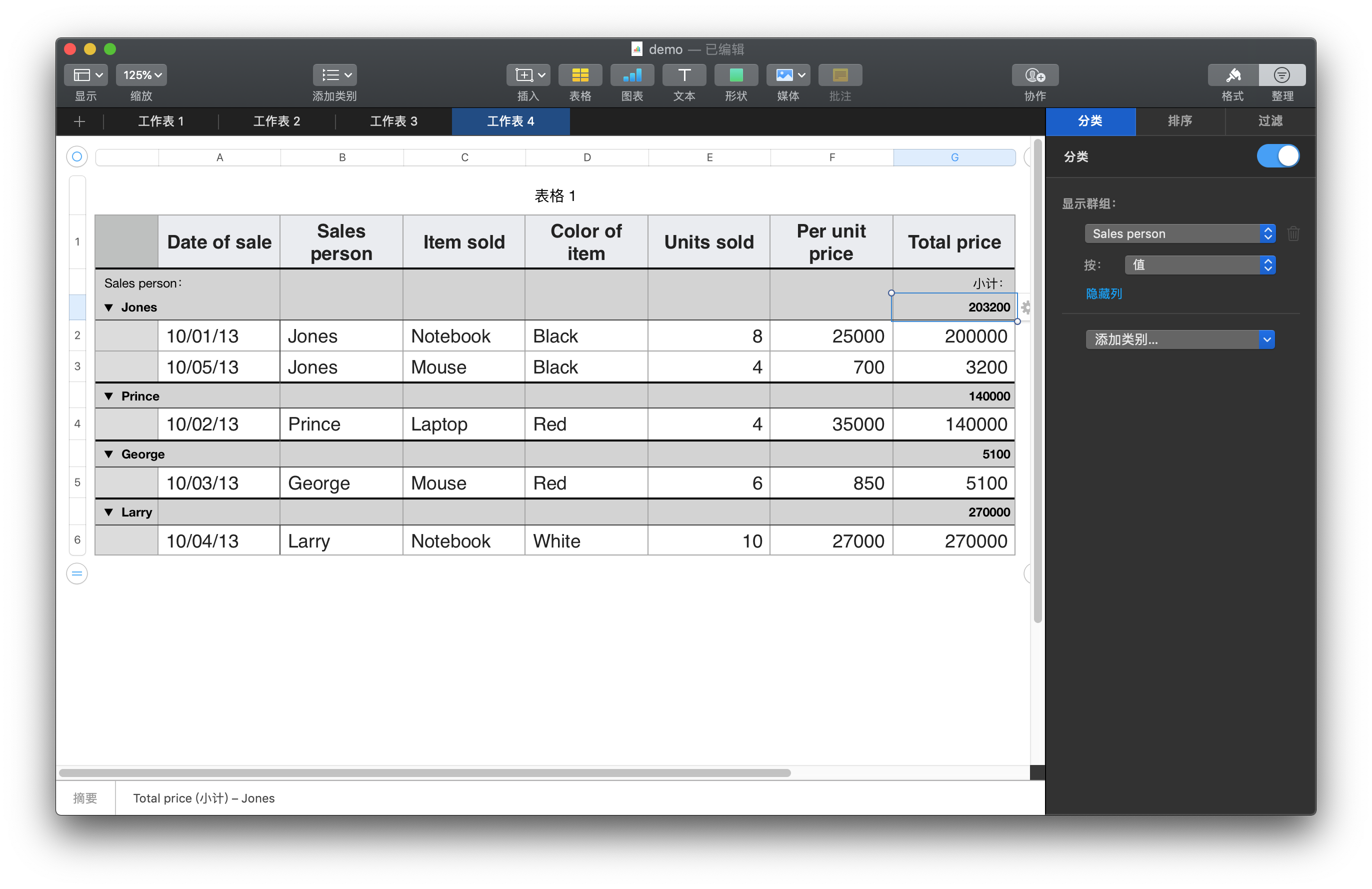
 除了Excel之外,许多现代数据分析工具都有数据透视表功能。但可能会有区别,下图是苹果公司推出的iWork套件中的Numbers软件对数据透视表的实现,Numbers并没有使用“数据透视表”这个词,而是用了“整理”来代替。
Numbers中的数据透视表
除了Excel之外,许多现代数据分析工具都有数据透视表功能。但可能会有区别,下图是苹果公司推出的iWork套件中的Numbers软件对数据透视表的实现,Numbers并没有使用“数据透视表”这个词,而是用了“整理”来代替。
Numbers中的数据透视表
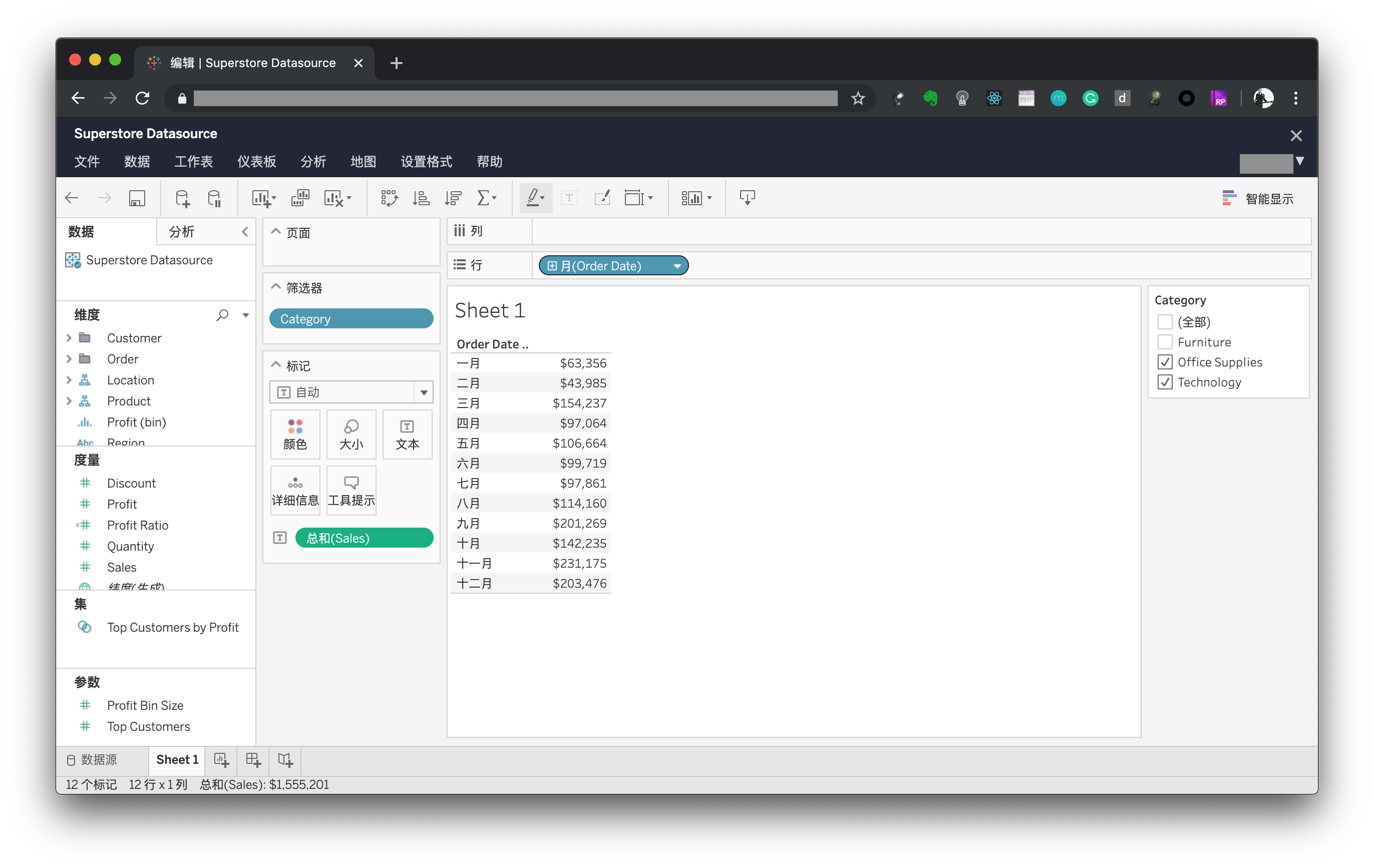
 tableau试图在数据侧增加一些定义,将数据字段分为了纬度和度量,并且将可视化也集成在分析过程中。目前有一些BI工具在效仿tableau的这种做法,集成越来越多的功能,但也使得软件上手越来越难,软件越来越重。
tableau中的数据透视表
tableau试图在数据侧增加一些定义,将数据字段分为了纬度和度量,并且将可视化也集成在分析过程中。目前有一些BI工具在效仿tableau的这种做法,集成越来越多的功能,但也使得软件上手越来越难,软件越来越重。
tableau中的数据透视表
内核
数据透视表的基本构成要素是不变的,一般会有以下四个要素:
- 数据源(datasource)
- 筛选条件(Report filter)
- 行、列标签(labels)
- 数值(Summation values)
*(也有一些软件没有把行标签和列标签区分开,例如Numbers只用了“群组”的概念来表示标签)
经典的数据透视表示意图
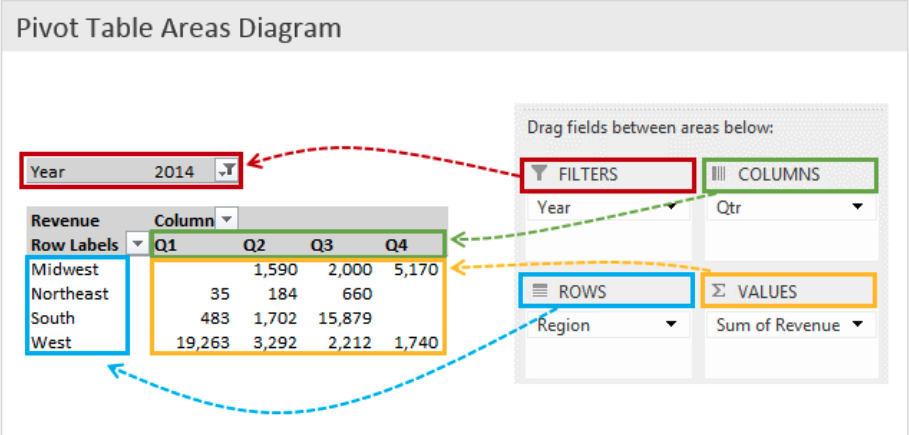
如果你学习过SQL语法,可能下面这段脚本会更有助于你理解上面这张图:
SELECT concat(<code>Qtr</code>,'###',<code>Region</code>) AS labels, sum(Revenue)
FROM datasource
WHERE Year = 2014
GROUP BY labels;将运行结果###两侧的Qtr和Region信息按照行和列展开,就是典型的数据透视表。 这时,GROUP BY就对应了全部的行标签、列标签,SELECT就对应了要查询的数值,WHERE就对应了筛选条件, FROM就对应了数据源.
因此,数据透视表的结构,就是对应了一个查询:
SELECT 标签:数值 FROM 数据源 WHERE 筛选 GROUP BY 标签这就是数据透视表的内核。
界面介绍
分析主界面
选择数据分析模块,进入分析主界面。
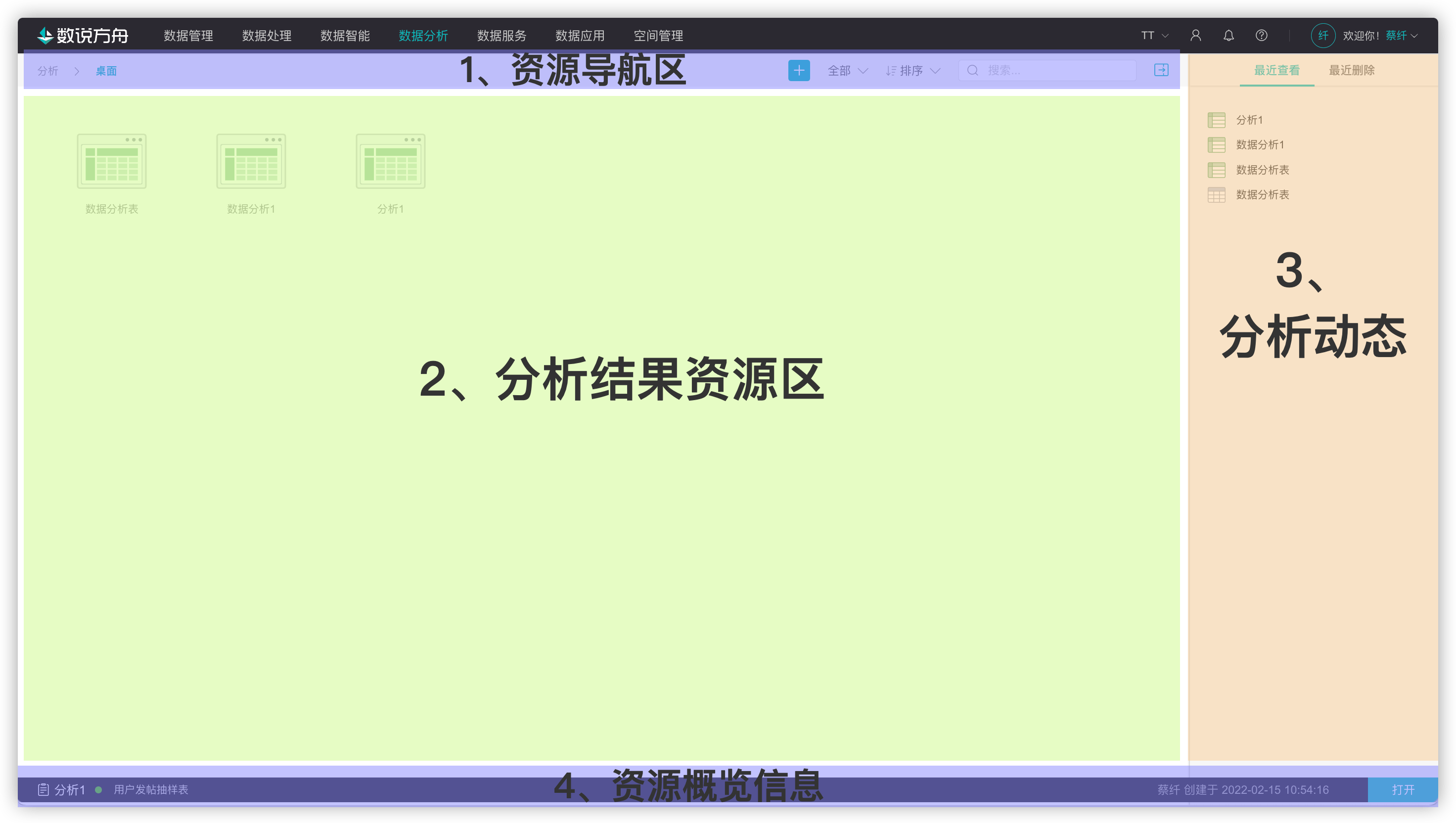
1.资源导航区
资源导航区包含了资源路径信息,资源筛选排序和关键字模糊查询。
- 筛选:按分析表类型筛选,默认展示全部类型。主要有全部、数据分析表、SQL分析表
- 排序:按分析表的属性排序。主要有 默认、创建时间、编辑时间、文件名、编辑者
- 检索:支持文件名模糊查询
2.分析结果资源区
展示项目内的全部分析表资源。支持文件夹归类存放。选中资源点击设置按钮,可以删除资源、编辑资源名称、资源描述信息、复制或移动到相关文件夹路径下。
3.分析动态
展示项目下数据分析模块的最近查看和最近删除分析表,其中最近删除下方的分析表,可做恢复。
4.资源概览信息
选中分析表后,下方出现资源概览信息,展示分析表的数据源及其状态,创建人及创建时间。
数据分析设计界面
方舟将透视表主要分成7个区域。

1.头部栏
头部栏包含了透视表的描述信息,包括透视表的名称、存储路径、创建者、创建时间,以及透视表的最后修改者,最后修改时间。
透视表的名称可以实时编辑,鼠标点击即可进入编辑模式,编辑完毕之后可通过回车键保存。
2.字段选择栏
字段选择栏的数据源名称之前会有一个圆形标识符,标示数据源集群当前的健康状态:
- 绿点:数据源状态良好
- 黄点:数据源状态不佳
- 红点:数据源出现严重问题,几乎无法访问
- 紫点:数据源无法访问
数据源名称的图标展示其数据库类型。
字段选择栏会列出数据源的全部字段供用户选择。用户可以用鼠标拖拽的方式,将字段拖拽到筛选器中,或者透视选择框中。
如果字段有分组(可通过字段分组了解),此处也会按照分组之后的信息来展示。
一个数据源有哪些字段,属于数据的元数据(metadata)信息,因此对于字段的显示符合元数据更新规则——即接入该数据源的全部业务方必须至少有一方手动更新了元数据,才会显示最新的metadata信息。
部分字段可能有别名,字段选择栏显示字段名的规则是:若有别名则显示别名,无别名则显示数据库中保存的真实字段名。
不同的字段可能有不同的字段类型。方舟会按照数值 长文本 短文本 日期时间 嵌套区分字段类型(字段类型).
其中嵌套类型字段可以在字段选择栏中展开,实际分析的时候对内层字段操作。
3.筛选器
用户可以将“字段选择栏”中的字段拖拽到筛选器中,并编辑筛选条件和筛选逻辑。筛选结果可以在 7.筛选结果 区域进行预览。
对于筛选条件和筛选逻辑的编辑规则,在后文 [数据透视表-筛选器 ] 操作详述。
4.透视选择框
用户可以将“字段选择栏”中的字段拖拽到透视选择框中,对 经过筛选的数据源 进行数据透视。数据透视结果会默认以表格的形式展示在 5.透视结果 区域中。
对于透视操作的规则和预期的透视结果,在后文 数据透视表-透视选择 详述。
5.透视结果
用户将字段放入透视选择栏进行透视操作之后,透视结果将以表格的形式显示在透视结果中。
用户可以对透视结果进行数据可视化操作,在右侧 6.可视化方案栏 可以选择具体的可视化方案。
6.可视化方案栏
选择一种图表,这种图表将会应用在 5.透视结果 区域的数据上。默认为表格。
对于透视所得到的数据,并非所有的图表类型都与其匹配。当透视结果无法渲染所选图表的时候,图表会呈现无数据的状态。
7.筛选结果
筛选器的筛选结果会显示在此处。右上角会显示符合筛选条件的数据的总数,用户可以预览50条数据,或者向下翻页加载更多数据。 右上角工具栏支持 拆分嵌套字段 显示字段 导出 全屏展示 。


产品咨询
020-38061725

微信扫描二维码在线咨询